O Spark é uma ferramenta que permite processar grandes volumes de informações, como explicado neste artigo do Eiti Kimura. As operações aplicadas nos datasets são variadas, incluindo filtros, agregações, algoritmos de aprendizagem de máquina e gráficos de visualização. Também são usadas com diferentes objetivos para gerar insights a partir dos dados.
O Spark Notebook é uma ferramenta (similar ao Jupyter Notebook) que possibilita programar um notebook, que é um arquivo composto por células que possuem código ou texto, é também executar célula a célula, conectado ao Spark. Na prática, após criar o notebook temos um pipeline, que é um fluxo de manipulação dos dados, contendo processos como:
- Leitura dos datasets;
- Limpeza e transformações dos dados;
- Geração de novas features;
- Enriquecimento a partir de outros datastores;
- Treino de modelos de aprendizagem de máquina;
- Visualização dos dados;
- e obtenção de insights.
Na Figura 1, temos um exemplo do uso do Spark Notebook com a execução de uma célula que gera como saída um gráfico:
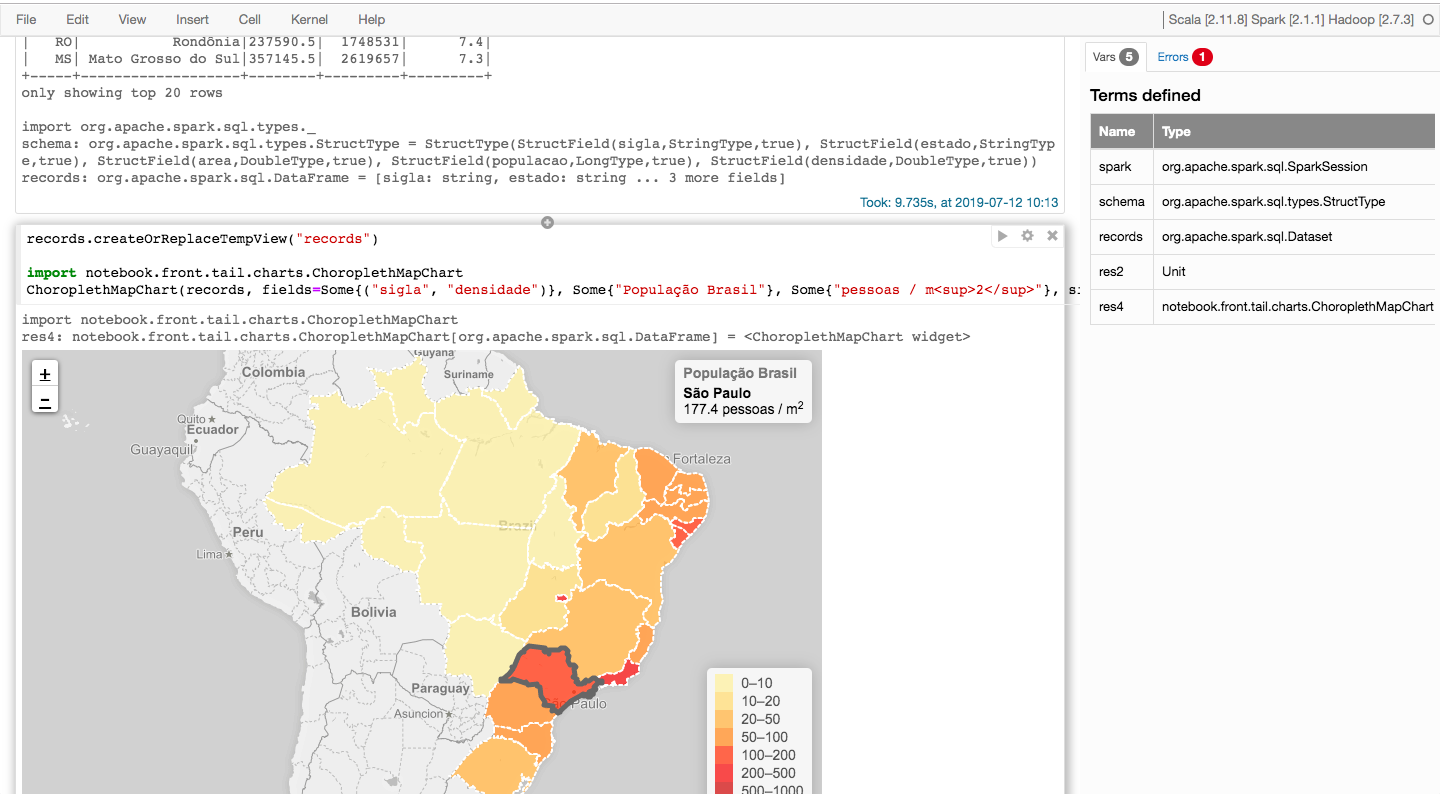
Figura 1: Exemplo da execução de uma célula no Spark Notebook.
O uso dos notebooks facilitam a exploração dos datasets, mas apresentam desafios como: o reaproveitamento dos códigos usados nos notebooks para exploração e que depois precisam ser executados em produção, agendamento da execução dos notebooks e visualização dos gráficos. Nesse artigo apresento como a Tail fez para automatizar o uso dos Spark Notebooks, conseguindo usar o mesmo notebook tanto para exploração como em produção.
A exploração dos dados é a etapa que permite conhecer o conteúdo do datasets aplicando diversas transformações para gerar insights. No Spark, muitas vezes essa exploração é feita por meio de uma ferramenta de notebook, permitindo que a equipe de Cientistas de Dados crie o código em partes, as quais são agrupadas em células. Logo após a criação de uma célula, podemos executar esse código e obter seu resultado, tanto no formato de texto como também com gráficos, tendo assim um ambiente interativo de exploração.
A exploração dos dados usando o notebook é feita normalmente por meio das operações fornecidas pelo Spark ou criando códigos em Java, Python ou Scala. Uma das bibliotecas disponíveis para manipulação dos dados é o Spark SQL que fornece a opção de executar instruções no formato SQL nos seus datasets.
Com o uso dos notebooks também temos alguns problemas:
- Ao explorar um dataset, o ideal é realizar essa exploração em cima de uma amostra desse dataset, principalmente quando o dataset é muito extenso, porque nesse momento ainda estamos conhecendo o dataset ou tentando obter informações e por causa do tempo de processamento necessário para realizar as operações nesses dados. Mas após a exploração precisamos mudar o dataset para usar a sua versão completa;
- Normalmente os notebooks de experimentação são criados pela equipe de Cientistas de Dados, que após finalizar as operações e validar os resultados, enviam o notebook para a equipe de Engenharia de Dados, que faz a programação para que o pipeline seja executado periodicamente no ambiente de produção;
- Um notebook não é o melhor ambiente para que os clientes e outros interessados visualizem os dados ou gráficos que o pipeline produziu, pois estes gráficos estarão disponíveis em uma interface que contém também os códigos que o produziram. Idealmente, os clientes deveriam ver seus gráficos em um ambiente próprio para isso, como um dashboard composto de gráficos produzidos por diferentes pipelines; e obtido os dados manipulados em um formato de arquivo que pode servir de carga para algum outro uso.
Na Tail executamos mais de 5 mil pipelines por dia, isso sem levar em consideração os pipelines que demoram mais de 24 horas para executar. Se fôssemos executar todos os pipelines a partir de um sistema de criação de notebooks, precisaríamos alocar várias pessoas de uma equipe de Engenharia de Dados só para isso, diariamente.
Como forma de facilitar o uso dos notebooks, criamos um sistema que executa diretamente arquivos no formato do Spark Notebook. (No GitHub do Spark Notebook há um exemplo desse arquivo.) O Spark Notebook é escrito em Scala, o que fizemos foi empacotá-lo como dependência no nosso projeto. Assim chamamos diretamente o código para executar célula a célula dos notebooks, e também temos a opção de passar como parâmetro qual dataset usar no notebook.
Com a possibilidade de executar os Spark Notebooks, o mesmo notebook criado para explorar os dados é também utilizado em produção. Dependendo do uso dentro do notebook para manipular ou apenas consultar os datasets, identificamos se há necessidade de bloquear ou não o acesso ao datastore, e se for necessário bloquear algum dataset, os demais notebooks são enfileirados e aguardam sua vez para serem executados.
Também agendamos a execução de cada notebook e após a execução aproveitamos para guardar o log da saída, que é gerado pelo próprio Spark Notebook com o resultado da execução, célula a célula. Esse log é usado caso ocorra problemas na execução do notebook e permite entender a causa do erro. Além disso, copiamos os gráficos gerados para fora do log de execução; assim podemos apresentá-los em um dashboard com uma interface mais agradável, possibilitando até a alteração da ordem e posição do gráfico; e exportamos os datasets gerados dentro do notebook para o formato de arquivo.
Na Figura 2, temos um resumo da arquitetura criada para automatizar a execução dos notebooks, e essa mesma arquitetura é usada tanto para exploração usando datasets contendo uma amostra do dataset original, como também a execução após serem agendados para executar com o dataset completo.

Figura 2: Arquitetura da execução automatizada de Spark Notebooks.
O Spark Notebook vem com alguns gráficos como: barras, pizza, grafo e mapas; mas para visualizações mais complexas, precisamos implementar novos gráficos. O Spark Notebook permite implementar nossos próprios gráficos, seguindo um padrão da sua documentação, então criamos um módulo específico para geração de novos gráficos e importamos como uma biblioteca externa, assim podemos executar os notebooks usando os nosso gráficos.
Com essas mudanças conseguimos facilmente executar em produção o notebook criado na exploração, agendando quando cada notebook deve ser executado. E temos um dashboard interessante para visualizar os gráficos gerados.
Na palestra Construção de Data Pipelines em Apache Spark, a Fabiane Nardon (Chief Data Scientist na Tail) explica como automatizamos a criação e execução de pipelines.
Sobre o autor
 Rafael Sakurai (@rafaelsakurai) é líder técnico na equipe de engenharia de Big Data da Tail e editor responsável pelo conteúdo de IA, ML e Engenharia de Dados do InfoQ Brasil. Trabalha com desenvolvimento de aplicações corporativas a mais de 15 anos, possui interesse em desenvolvimento de soluções distribuídas, aprendizado de máquinas e ciência de dados.
Rafael Sakurai (@rafaelsakurai) é líder técnico na equipe de engenharia de Big Data da Tail e editor responsável pelo conteúdo de IA, ML e Engenharia de Dados do InfoQ Brasil. Trabalha com desenvolvimento de aplicações corporativas a mais de 15 anos, possui interesse em desenvolvimento de soluções distribuídas, aprendizado de máquinas e ciência de dados.