Pontos Principais
- Várias tendências recentes sobre dados estão gerando uma mudança radical no velho mundo de arquitetura em batch ETL (Extract-Transform-Load): as plataformas de dados operam em todas as empresas de forma escalar; Existem muitos mais tipos de fontes de dados; e fluxo de dados é cada vez mais onipresente;
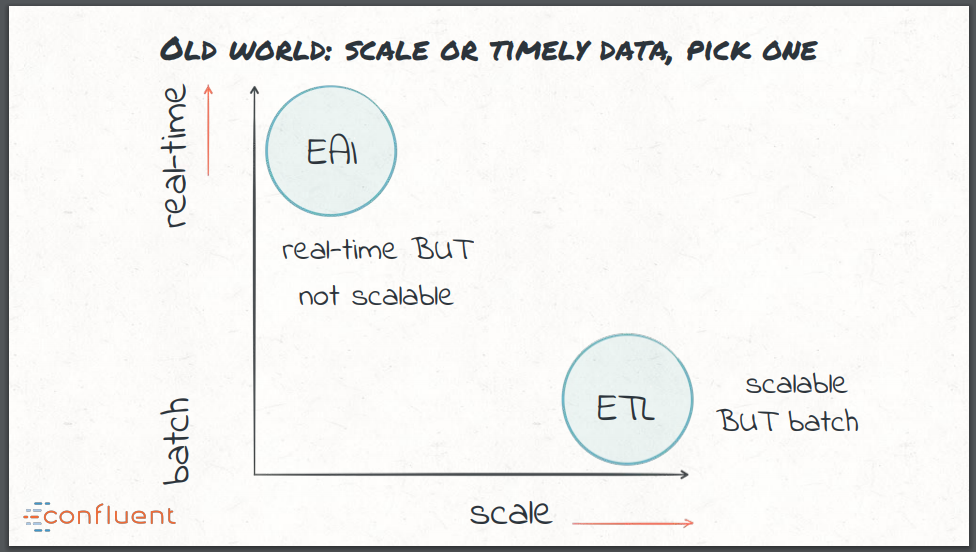
- A Integração de Aplicações Corporativas (EAI) foi uma proposição antecipada ao modelo ETL para processamento em tempo real, mas as tecnologias usadas geralmente não eram escaláveis. Isso levou a uma escolha difícil com a integração de dados no mundo antigo: em tempo real, mas não escalável ou escalável mas em lote.
- O Apache Kafka é uma plataforma de streaming de código aberto que foi desenvolvida há oito anos no LinkedIn
- O Kafka permite a construção de pipelines de dados de streaming de "origem" para "destino" por meio da API Kafka Connect e da API Kafka Streams
- Os logs unificam o processamento em lote e em stream. Um log pode ser consumido através de "janelas" em lote ou em tempo real, examinando cada elemento à medida que chegam
Na QCon San Francisco 2016, Neha Narkhede apresentou a palestra "ETL Is Dead; Long Live Streams "e discutiu a mudança do cenário do processamento de dados corporativos. Uma premissa central da conversa foi que a plataforma de streaming Apache Kafka de código aberto pode fornecer uma estrutura flexível e uniforme que suporte os requisitos modernos de transformação e processamento de dados.
Neha Narkhede, uma das co-fundadoras e CTO da Confluent, iniciou sua palestra afirmando que os dados e sistemas de dados mudaram significativamente na última década. O mundo antigo normalmente consistia em bancos de dados operacionais que fornecem processamento de transações on-line (OLTP) e armazéns de dados relacionais que fornecem processamento analítico on-line (OLAP). Os dados de uma variedade de bancos de dados operacionais geralmente eram carregados em lote em um esquema mestre no data warehouse, uma ou duas vezes por dia. Esse processo de integração de dados é comumente chamado de ETL (extração-transformação-carga).
Várias tendências recentes para tratamento de dados estão gerando uma mudança radical na arquitetura ETL do velho mundo como por exemplo:
- Bancos de dados em servidor único estão sendo substituídos por uma miríade de plataformas de dados distribuídos que operam em escala por toda a empresa.
- Existem muitos mais tipos de fontes de dados além dos dados transacionais: por exemplo, logs, sensores, métricas, etc.
- Os dados em stream são cada vez mais onipresentes e há uma necessidade comercial de processamento mais rápido do que processamento em batch.
O resultado dessas tendências é que as abordagens tradicionais à integração de dados geralmente acabam parecendo uma bagunça, com uma combinação de scripts de transformação personalizados, middleware corporativo, como barramento de serviço corporativo (ESBs) e tecnologia de fila de mensagens (MQ) e tecnologia de processamento como o Hadoop.
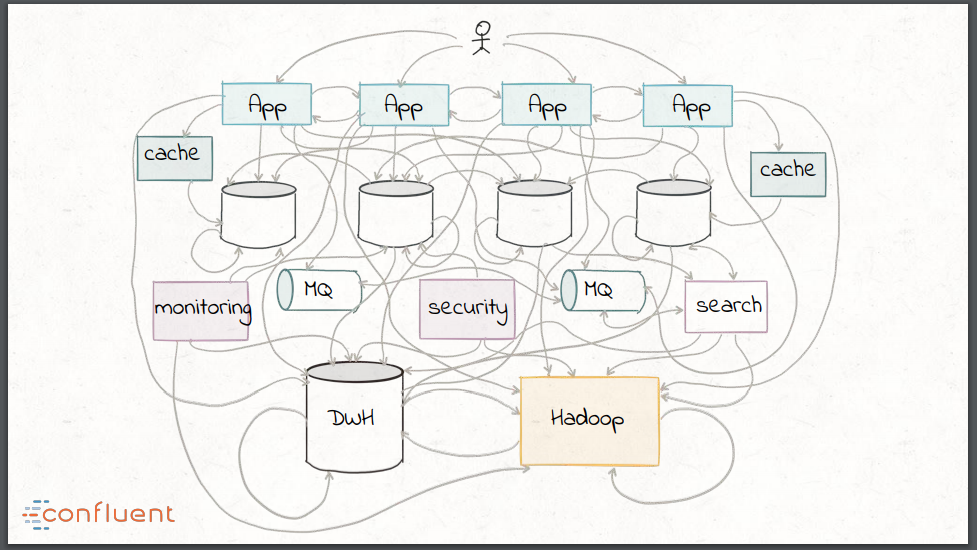
Antes de explorar como a transição para a moderna tecnologia de streaming poderia ajudar a aliviar esse problema, Neha Narkhede mergulhou em um breve histórico de integração de dados. A partir da década de 1990, no setor de varejo, as empresas se tornaram cada vez mais interessadas em analisar as tendências dos compradores com as novas formas de dados agora disponíveis para eles. Os dados operacionais armazenados nos bancos de dados OLTP precisavam ser extraídos, transformados no esquema do warehouse de destino e carregados em um data warehouse centralizado. Como essa tecnologia amadureceu nas últimas duas décadas, no entanto, a cobertura de dados nos data warehouses permaneceu relativamente baixa devido aos inconvenientes do ETL:
- Existe a necessidade de um esquema global.
- A limpeza e a curadoria de dados são manuais e fundamentalmente propensas a erros.
- O custo operacional do ETL é alto: geralmente é lento e consome tempo e recursos.
- As ferramentas de ETL foram criadas para focar estreitamente a conexão de bancos de dados e o data warehouse por meio de um processo batch.
A integração de aplicações corporativas (EAI) foi uma proposição antecipada de um ETL em tempo real e utilizou ESBs e MQs para integração de dados. Embora eficaz para processamento em tempo real, essas tecnologias muitas vezes não poderiam ser dimensionadas para a magnitude necessária. Isso levou a uma escolha difícil com a integração de dados no mundo antigo: em tempo real, mas não escalável, ou escalável mas em um processo em batch.
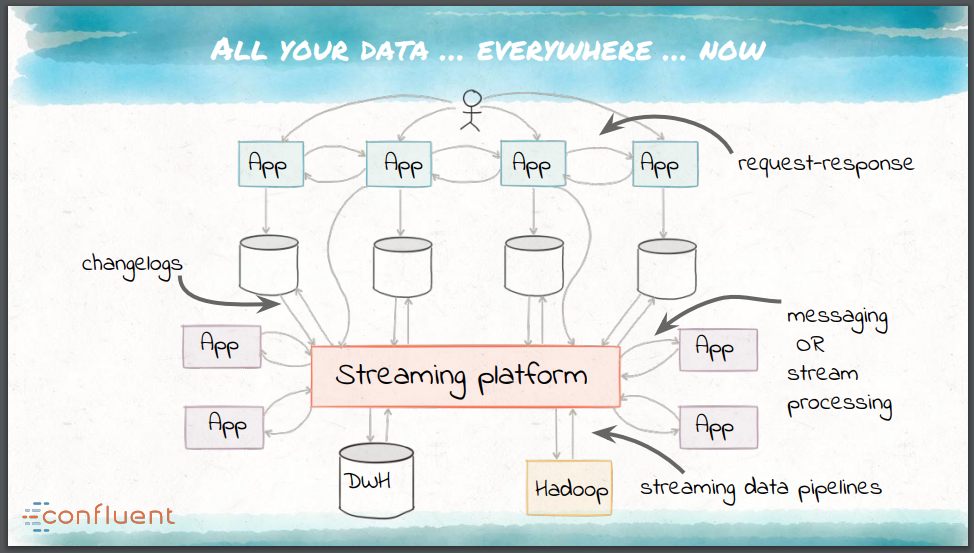
Neha Narkhede argumentou que o mundo moderno de streaming tem novos requisitos para integração de dados:
- A capacidade para processar alto volume de dados assim como uma alta diversidade de dados.
- Uma plataforma deve ter suporte para tempo real a partir do zero, o que leva a uma transição fundamental para o pensamento centrado em eventos (event-centric thinking).
- As arquiteturas de dados compatíveis com o encaminhamento devem estar ativadas e devem poder suportar a capacidade de adicionar mais aplicações que precisam processar os mesmos dados de formas diferentes.
Esses requisitos impulsionam a criação de uma plataforma unificada de integração de dados, em vez de uma série de ferramentas sob medida. Essa plataforma deve adotar os princípios fundamentais da arquitetura e infraestrutura modernas, e deve ser tolerante a falhas, ser capaz de paralelismo, suportar semânticas de entrega múltiplas, fornecer operações e monitoramento eficazes e permitir o gerenciamento de esquemas. O Apache Kafka, desenvolvido oito anos atrás no LinkedIn, é uma dessas plataformas de streaming de código aberto e pode funcionar como o sistema nervoso central para os dados de uma organização das seguintes maneiras:
- Ele serve como o barramento de mensagens escalável em tempo real para aplicativos, sem a necessidade de um EAI.
- Ele serve como o canal de origem única da verdade para alimentar todos os destinos de processamento de dados.
- Ele serve como bloco de construção para microservices de processamento de stream stateful.
O Apache Kafka processa 14 trilhões de mensagens por dia no LinkedIn e é implantado em milhares de organizações em todo o mundo, incluindo empresas da Fortune 500, como Cisco, Netflix, PayPal e Verizon. O Kafka está rapidamente se tornando o armazenamento preferido dos dados de streaming e oferece um backbone de mensagens escalável para integração de aplicações que pode abranger vários datacenters.
É fundamental para o Kafka o conceito do log; uma estrutura de append-only com uma estrutura de dados totalmente ordenada. O log se presta a semântica de publicação/assinatura (pubsub), já que um publisher pode facilmente anexar dados (append) ao log de forma imutável e monotônica, e os assinantes (subscribers) podem manter seus próprios ponteiros para indicar o processamento de mensagens atuais.
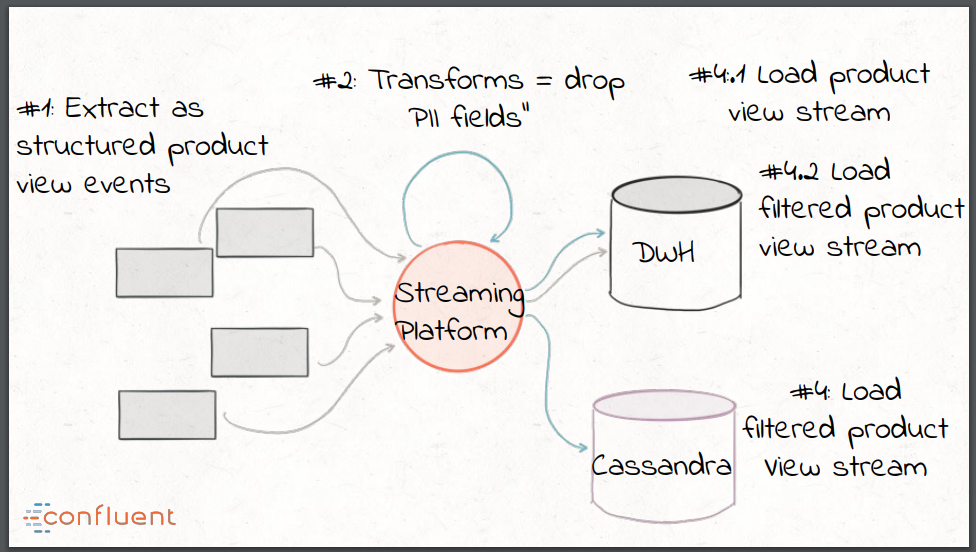
O Kafka permite a construção de pipelines de dados em streaming - o E e o L em ETL - por meio da API do Kafka Connect. A API Connect aproveita o Kafka para escalabilidade, baseia-se no modelo de tolerância a falhas do Kafka e fornece um método uniforme para monitorar todos os conectores. O processamento de stream e as transformações podem ser implementados usando a API Kafka Streams - isso fornece o T no ETL. O uso do Kafka como uma plataforma de streaming elimina a necessidade de criar (potencialmente duplicar) extratos personalizados, transformar e carregar componentes para cada destino, data store ou sistema de destino. Os dados de uma fonte podem ser extraídos uma vez como um evento estruturado na plataforma e qualquer transformação pode ser aplicada por meio do processamento do stream.
Na seção final da palestra, Neha Narkhede examinou o conceito de processamento de stream - transformações em stream de dados - com mais detalhes e apresentou duas visões concorrentes: MapReduce em tempo real versus microservices acionados por eventos. O MapReduce em tempo real é adequado para casos de uso analítico e requer um cluster central e empacotamento, implementação e monitoramento personalizados. O Apache Storm, Spark Streaming e Apache Flink implementam isso. Neha Narkhede argumentou que a visão de microservices orientada a eventos - que é implementada pela API Kafka Streams - torna o processamento de stream acessível para qualquer caso de uso e requer apenas a adição de uma biblioteca incorporada a qualquer aplicativo Java e um cluster Kafka disponível.
A API Kafka Streams fornece uma conveniente e fluente DSL, com operadores como por exemplo join, map, filtros e janelas agregadas.

Esse é o verdadeiro processamento de evento por vez em stream - não há micro batch processamento - e usa uma abordagem de janelas no estilo de dados em stream com base no tempo do evento para manipular dados que chegam de forma tardia. O Kafka Streams fornece suporte pronto para uso para o estado local e suporta processamento stateful e tolerante a falhas. Ele também suporta o reprocessamento de stream, que pode ser útil ao atualizar aplicações, migrar dados ou realizar testes A/B.
Neha Narkhede concluiu a palestra afirmando que os logs unificam o processamento em lote e em stream - um log pode ser consumido por meio de janelas em lote ou em tempo real examinando cada elemento à medida que chega - e que o Apache Kafka pode fornecer o "novo futuro brilhante do ETL".
O vídeo completo do QCon SF apresentado por Neha Narkhede que fala sobre "ETL is Dead; Long Live Streams" pode ser encontrado no InfoQ.
About the Author
 Daniel Bryant lidera a mudança dentro de organizações e da própria tecnologia. Seu trabalho atual inclui a habilitação de agilidade nas organizações, introduzindo melhores técnicas de coleta e planejamento de requisitos, concentrando-se na relevância da arquitetura no desenvolvimento ágil e facilitando a integração/entrega contínua. A experiência técnica atual de Daniel se concentra nas ferramentas de 'DevOps', nas plataformas em nuvem/container e nas implementações de microservices. Ele também é líder na London Java Community (LJC), contribui para vários projetos de código aberto, escreve para sites técnicos conhecidos, como InfoQ, DZone e Voxxed, e apresenta regularmente em conferências internacionais como QCon, JavaOne e Devoxx.
Daniel Bryant lidera a mudança dentro de organizações e da própria tecnologia. Seu trabalho atual inclui a habilitação de agilidade nas organizações, introduzindo melhores técnicas de coleta e planejamento de requisitos, concentrando-se na relevância da arquitetura no desenvolvimento ágil e facilitando a integração/entrega contínua. A experiência técnica atual de Daniel se concentra nas ferramentas de 'DevOps', nas plataformas em nuvem/container e nas implementações de microservices. Ele também é líder na London Java Community (LJC), contribui para vários projetos de código aberto, escreve para sites técnicos conhecidos, como InfoQ, DZone e Voxxed, e apresenta regularmente em conferências internacionais como QCon, JavaOne e Devoxx.