Pontos Principais
- Escolher um processador de stream é desafiador porque existem muitas opções e a melhor escolha depende do caso de uso do usuário final.
- Streaming SQL provê benefícios significativos com tempos de desenvolvimento de aplicações mais rápidos e implantações altamente sustentáveis.
- Ambientes de escrita de consultas afetam de forma significativa a produtividade do desenvolvedor, o que exige editores gráficos avançados e depuradores de aplicações para processador de stream.
- Se um sistema precisa transferir menos de 50 mil eventos por segundo, é possível ter maior economia ao fazer deploy de alta disponibilidade (HA) de dois nós.
- Se a taxa de eventos está além de um único nó de processamento de stream, é necessário acomodar os eventos que chegam em um broker de mensagens e processar os eventos com snapshot habilitado.
Processadores de stream são plataformas de softwares que permitem aos usuários responder rapidamente aos streams de dados que chegam (veja mais em O que é processamento de stream?).
Aplicações de streaming na qual executam processadores de stream possuem muitas formas.
A seguir estão alguns exemplos:
- Detectar uma condição e gerar um alerta (por exemplo, rastrear a temperatura de um aparelho de cozinha e criar um alerta se exceder um limite pré-definido);
- Calcular a localização média de um objeto em movimento e atualizar uma página web (por exemplo, detectar a localização de uma pessoa e traçar sua trajetória em um mapa);
- Detectar anomalias e atuar sobre elas (por exemplo, detectar um usuário suspeito e fazer uma análise detalhada de suas ações).
Se você está curioso sobre outras aplicações, a publicação no blog 13 Padrões de Processadores de Stream para Construção de Aplicações de Streaming e em tempo-real aborda mais casos de uso.
Como descrito em uma questão no Quora "Quais são as melhores soluções de processadores de stream?", há muitas opções de processadores de stream disponíveis para serem escolhidos.
A escolha depende do caso de uso e se deve escolher o processador de stream que melhor corresponde ao seu caso de uso.
Este artigo discute como fazer a escolha.
Vamos abordar este problema em três passos. Discutiremos primeiro uma arquitetura de referência; a anatomia de uma aplicação de streaming.
Então discutiremos características chaves requeridas pela maioria das aplicações de streaming.
Finalmente, vamos listar características opcionais que podem ser selecionadas de acordo com o caso de uso.
Arquitetura de referência para aplicações de streaming
Uma aplicação de streaming precisa de três coisas: streams de dados, um processador para processar os dados e código para fazer algo com as decisões (ver figura 1).

Figura 1: Arquitetura de referência para aplicações de streaming
Primeiro, colete todos os streams de dados recebidos das fontes em filas de mensagens de um intermediário. A menos que tenha requisitos específicos que garanta um projeto diferente, recomendamos que armazene as mensagens em uma fila de mensagens e leia as mensagens a partir desta fila. Isto permite repetir eventos se necessário e simplificar a alta disponibilidade (HA) e tolerância à falhas.
O processador de stream busca os eventos na fila de mensagens, os envia para a consulta de stream, no qual processa os dados e gera os resultados. Muitos processadores de stream ajudam na atuação sobre esses resultados ao gerar alertas, expondo ou invocando APIs, executando ações e disponibilizando visualizações. Por exemplo, vamos considerar o primeiro cenário mencionado na seção de introdução, no qual monitora a temperatura numa sala para detectar anomalias no uso de energia. A aplicação detecta e notifica anormalidades via e-mails de alerta. A figura 2 apresenta o gráfico do fluxo de dados para este caso de uso.

Figura 2: Arquitetura de uma aplicação de processamento de stream para detectar aumento anormal da temperatura de uma sala.
Quando selecionar um processador de stream, considere dois tipos de características: as que precisam estar presentes e as que são boas de terem. Como os nomes sugerem, no primeiro caso são características necessárias. Mesmo que não as use agora, há chances de serem usadas em breve. Pode-se escolher características que são boas de terem de acordo com os requisitos. Este artigo tem como foco principal as características que são necessárias.
Características necessárias
Assegure que o processador de stream escolhido suporta todas as seguintes características.
Suporte à Ingestão de Dados com intermediário de mensagem
Durante o desenvolvimento da aplicação, a primeira questão que surge é "Como minha aplicação recebe dados de fontes externas?" A resposta é usar um intermediário de mensagem e garantir que o processador de stream possa fazer isto. A maioria deles pode. A seguir estão algumas vantagens em se usar um intermediário:
- Mensagens são armazenadas de forma persistente tão logo sejam recebidas;
- O intermediário se tornará o ponto final de alta disponibilidade. O resto do sistema não precisa de alta disponibilidade:
- Se algo dá errado, pode-se voltar a repetir a mensagem a partir do intermediário de mensagem;
- Intermediários de mensagem escaláveis como o Kafka já lidam com as complexidades de escalabilidade.
Para explorar os méritos de um intermediário de mensagem, por favor consulte os artigos Questionando a Arquitetura Lambda e Log: O que todo engenheiro de software deve saber sobre abstração para unificar dados em tempo-real.
Streaming SQL
A primeira geração de mecanismos de streaming como Apache Storm e Apache Spark exigiam que os usuários escrevessem código. Os usuários escreviam o código e os colocavam dentro de um agente (às vezes chamados de ator). Os mecanismos de streaming permitem aos usuários conectarem estes agentes e ingerir eventos.
Embora esta seja uma ótima maneira de iniciar, faz-se necessário que os usuários escrevam código. Isso pode levar a códigos duplicados em múltiplos locais, os quais levam ao aumento do custo de manutenção.
Imagine que é necessário obter dados de um banco; será necessário escrever código descrevendo como encontrar os dados. Escrever código para processamento de stream não é o melhor a se fazer. O processamento em lote já mudou da escrita de código e, em vez disso, suporta consultas via SQL. Podemos fazer o mesmo com a análise de streaming. Tal linguagem de consulta é chamada Streaming SQL.
A seguir estão algumas vantagens em linguagem de streaming SQL:
- É fácil seguir e fácil contratar muitos desenvolvedores que já conhecem SQL.
- É expressiva, curta, amigável e rápida.
- Define operações centrais que cobrem 90% dos problemas.
- Especialistas em linguagem de streaming SQL podem implementar análises customizadas específicas às aplicações ao escreverem extensões.
- Um mecanismo de consulta pode otimizar melhor as execuções com um modelo de streaming SQL.
Com Streaming SQL, os usuários podem consultar os dados sem a necessidade de escrever código. A plataforma lida com a transferência de dados, análise de dados e também provê operadores, tais como união, janelas e padrões, diretamente na linguagem. A listagem 1 mostra o código de Streaming SQL para a aplicação anteriormente mencionada para detecção de anomalias.
Listagem 1: Aplicação para detecção de anomalia de alta temperatura em uma sala
@App:name("High Room Temperature Alert")
@App:description('An application which detects abnormal increase of room temperature.')
@source(type='kafka', @map(type='json'), bootstrap.servers='localhost:9092',topic.list='inputStream',group.id='option_value',threading.option='single.thread')
define stream RoomTemperatureStream(roomNo string, temperature double);
@sink(type='email', @map(type='text'), ssl.enable='true',auth='true',content.type='text/html', username='sender.account', address='sender.account@gmail.com',password='account.password', subject="High Room Temperature Alert", to="receiver.account@gmail.com")
define stream EmailAlertStream(roomNo string, initialTemperature double, finalTemperature double);
--Capture a pattern where the temperature of a room increases by 5 degrees within 2 minutes
@info(name='query1')
from every( e1 = RoomTemperatureStream ) -> e2 = RoomTemperatureStream [e1.roomNo == roomNo and (e1.temperature + 5.0) <= temperature]
within 2 min
select e1.roomNo, e1.temperature as initialTemperature, e2.temperature as finalTemperature
insert into EmailAlertStream;
Se o processador de stream não suportar Streaming SQL, desenvolver sua aplicação de streaming tomará mais tempo. Por exemplo, se fosse desenvolver a mesma aplicação mostrada na Listagem 1 em Java, seria gasto um volume de tempo significativo escrevendo código para detectar padrões. Além disso, uma vez implantado em produção, fazer manutenção na aplicação é muito caro. Uma aplicação de streaming precisaria de vários operadores, tais como transformação, agregação/correlação, janelas e correspondência de padrões. É necessário escrever estes algoritmos desde o início. Para aprender mais sobre streaming SQL, por favor, verifique o artigo Processamento de Stream 101: desde SQL até Streaming SQL.
APIs de processamento de stream e ambiente para escrita de consultas
Quais ferramentas o processador de stream fornece para desenvolver sua aplicação? Os mais conhecidos processadores de stream possuem um editor para criação de consultas, tanto na forma visual quanto textual. A figura a seguir (ver figura 3) mostra uma consulta feita com o WSO2 Stream Processor, um processador de stream open source disponibilizado com a licença Apache 2.0. Tal editor suporta mensagens de erros visuais e autocompletar (ver figura 3). Streaming SQL é uma linguagem poderosa, mas delicada. Ser capaz de ver a saída enquanto se escreve as consultas é muito útil. O primeiro nível é ser capaz de anexar um arquivo de eventos ao editor, repetir os eventos e ver a saída ao escrever uma consulta. O segundo nível é ter a saída alterada enquanto se altera a consulta.
(Clique na imagem para aumentá-la)
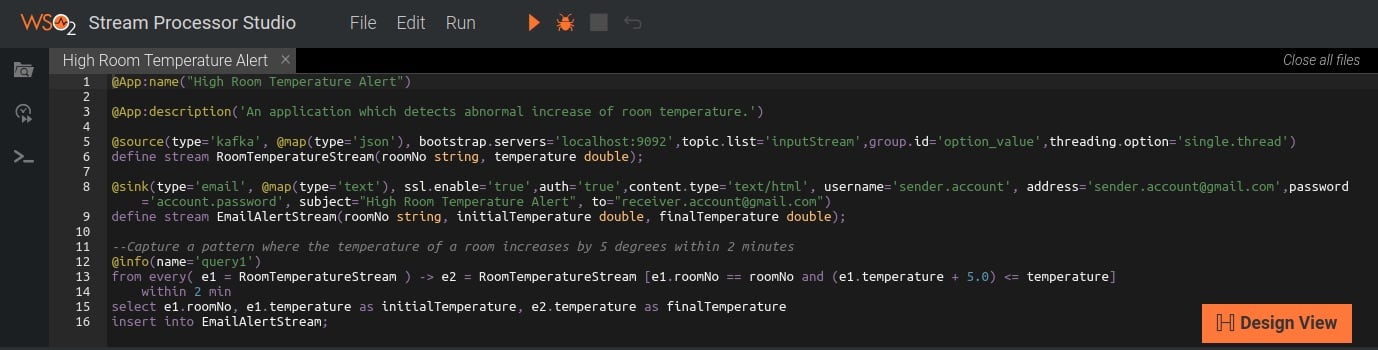
Figura 3: Stream Processor Studio mostra o código da aplicação de alerta de altas temperatura da sala
Quase todos os processadores de stream possuem algum suporte à depuração da aplicação. No entanto, o nível de suporte de depuração varia. Alguns depuradores permitem a inclusão de um ponto de parada e inspeção de valores e rastreio das variáveis intermediárias (ver figura 4). Outros fornecem logs de eventos. Alguns depuradores fornecem visibilidade à métricas, como contador do fluxo de eventos entre operadores.
Não ter qualquer suporte de depuração dificulta muito ao investigar o comportamento de uma aplicação de stream. Deve-se escolher um processador de stream que possui um extenso suporte à depuração. Que economize muita horas durante a criação de consultas e na manutenção.
(Clique na imagem para aumentá-la)
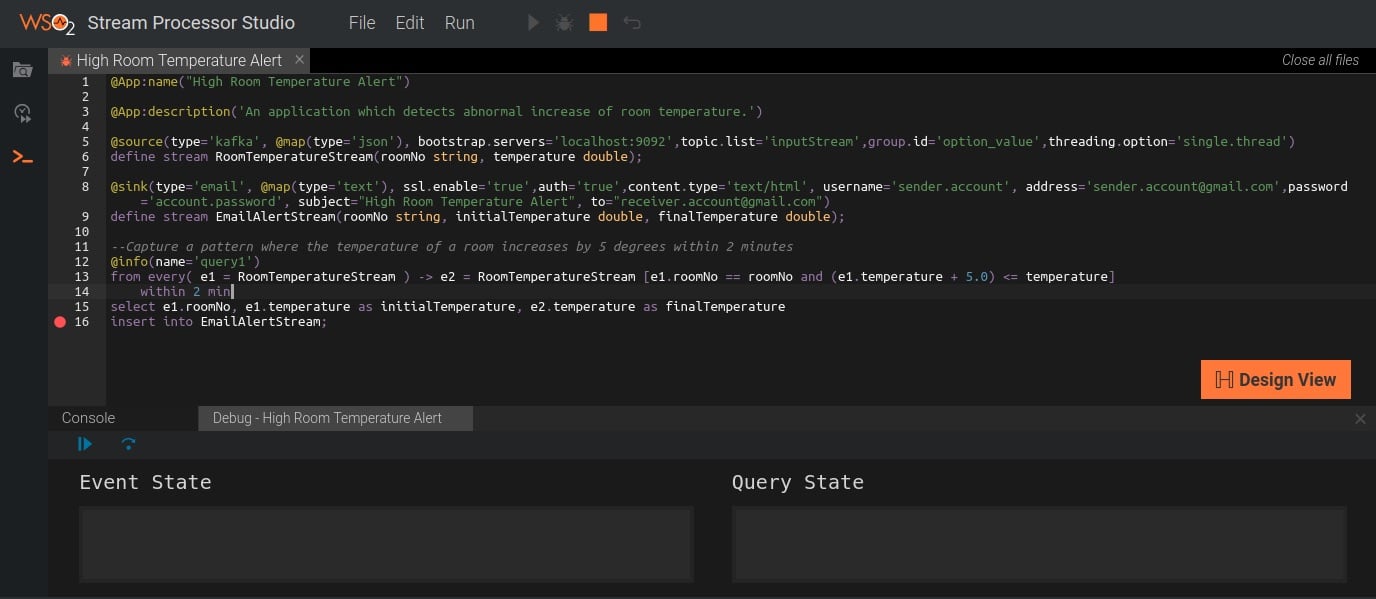
Figura 4: Depurando a aplicação de alerta de alta temperatura da sala com o Stream Processor Studio
Alguns processadores de stream também incluem Interfaces Gráficas do Usuário (GUIs em inglês) com opção de arrastar e soltar (ver figura 5). A GUIs com opção de arrastar e soltar fornece uma ferramenta com elementos que podem ser soltos e uma tela de rolagem bidirecional para soltar os elementos. A ferramenta pode ter ícones para definição de streams, operadores como janelas, junção e filtro. Uma vez que o usuário adiciona o operador de streaming à tela usando o arrastar e soltar, pode-se modificar propriedades de cada stream/operador ao usar o assistente de configuração do operador.
(Clique na imagem para aumentá-la)
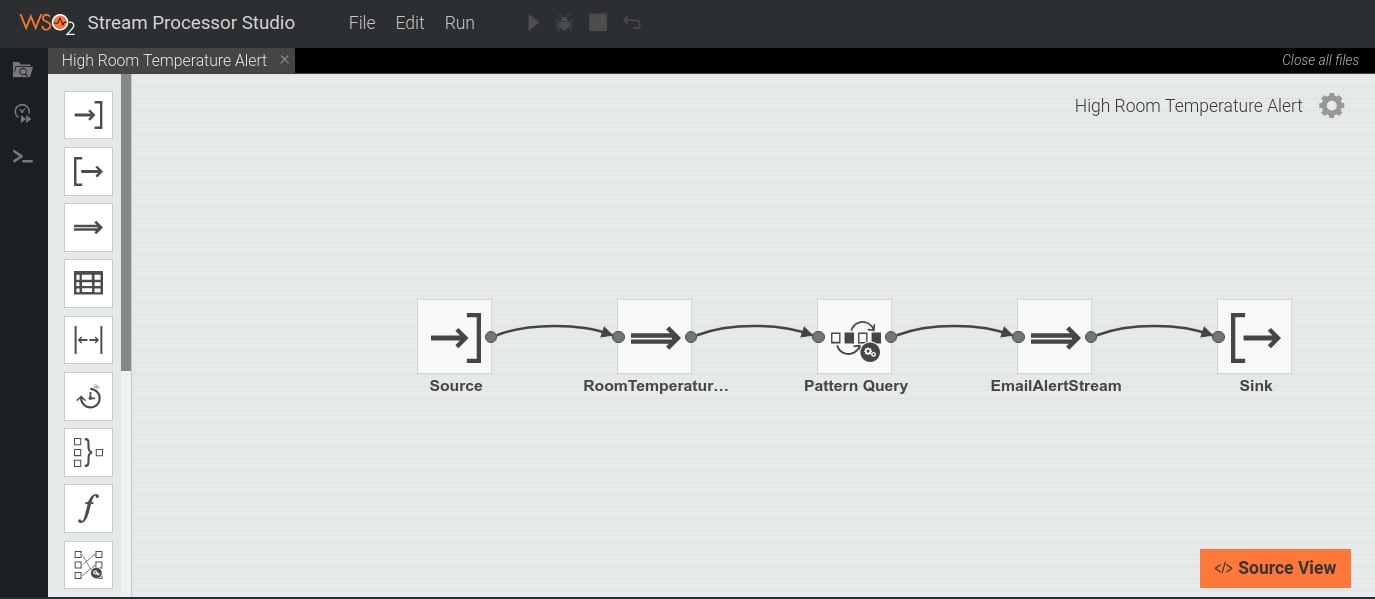
Figure 5: Editor gráfico do Stream Processor Studio mostrando o gráfico de fluxo de dados da aplicação de alerta de alta temperatura da sala
Enquanto fazem ótimas demonstrações, não está claro se uma interface com arrastar e soltar é melhor para a construção de aplicações. Por exemplo, tal interface não tem sido usada amplamente. A criação de consulta SQL é feita ao escrever SQL diretamente. É um mito que usuários de negócio que não entendem de programação podem escrever consultas com uma ferramenta de arrastar e soltar. Até mesmo esses usuários precisam entender programação para irem além do básico.
Confiabilidade, alta disponibilidade (HA) e alta disponibilidade Mínima
O que acontece se o sistema falha de repente? Aplicações de processamento de stream são executadas para sempre e nunca param. Por isso, se é uma aplicação que guarda o estado (dados), a aplicação eventualmente perderá informações valiosas (por exemplo, estado) devido à falhas no sistema. Chamamos a habilidade de recuperação de uma falha como "confiabilidade" e chamamos a habilidade de continuar as operações com o mínimo de interrupção como alta disponibilidade.
Gerenciamento de estado
A maioria das consultas de streaming guardam estados. Onde manter e como acessar os estados? O estado é a informação que o processador de stream lembra entre o processamento de dois eventos.
O estado tem três tipos: estado da Aplicação, estado do Usuário e estado do Sistema.
O estado da Aplicação refere-se aos valores criados e mantidos durante a execução da aplicação. Um exemplo é o estado necessário para detectar condições, como padrões ou conteúdo de uma janela de intervalo. O estado da Aplicação reside em um local temporário (ver figura 6), como a memória principal e periodicamente são salvos em um local permanente.
O estado do Usuário são dados do usuário que são acessados pela aplicação para tomar decisões em tempo de execução. Por exemplo, um local permanente como um Sistema de Gestão de Banco de Dados Relacional (RDBMS em inglês) pode conter informações do histórico de crédito do usuário.
O estado do Sistema refere-se a tudo o que o framework fornece para ter a certeza de que se o processador de stream falhar, este é recuperado novamente para suas operações normais.


Figura 6: Processador de stream de dados com armazenamento de dados
Processadores de stream altamente disponíveis precisam de gerenciamento de estado confiável e tolerância à falha para evitar a perda de estado. O estado do Usuário é armazenado diretamente em um local permanente. E os processadores de stream recuperam os estados de Aplicação e Sistema através de deploys ativos, snapshotting ou recomputação.
Após uma falha, a recomputação repete os eventos a partir do último estado bom e conhecido para continuar as execuções. No entanto, se a aplicação é do tipo que guarda o estado, o último estado bom e conhecido poderá ser o início. Isto frequentemente leva à repetição e reprocessamento de um alto número de eventos.
Para evitar ter que repetir um alto número de eventos, o processador de stream pode pegar o registro dos dados em um dado momento. Então, o processador de eventos pode restaurar o estado a partir de tal registro de dados e repetir os eventos desde então.
Deploy mínimo com alta disponibilidade
Em muitos processadores de stream, um único nó pode aguentar uma taxa acima de 50.000 eventos por segundo. A mais alta transferência requerida pela maioria dos casos de uso dos processamentos de stream ficam bem abaixo dos 50.000 eventos por segundo. Frequentemente, tais casos de uso não precisam escalar além de dois nós, que no caso, pode ter significativa economia ao fazer o deploy ativo descrito acima. Por exemplo, veja o artigo "Seu Processador de Stream está obeso?".
Pressão contrária
O que acontece se a aplicação recebe mais eventos do que pode suportar? Dentro dos processadores de stream, a pressão contrária mantém a estabilidade do sistema, recusando-se a aceitar eventos em excesso.
Se feito corretamente, a pressão contrária precisa ser feita em cada nível do processador de stream. A pressão contrária transfere o peso de um gargalo de volta para as origens dos eventos, evitando sobrecarga nas filas e erros de memória insuficiente. Desde que o processador de stream pare de aceitar novos eventos do sistema externo, os sistemas externos podem ter que guardar de forma temporária os dados ou até mesmo descartá-lo antes de ficarem sobrecarregados.
Se há escalonamento dinâmico, o sistema pode se autoescalar ao invés de adotar a pressão contrária. No entanto, nenhum sistema escala indefinitivamente, e quando alcança seu limite, será necessário empregar pressão contrária.
Esta é uma característica crítica a ser considerada durante a escolha de um processador de stream.
Recomendações para alta disponibilidade confiável
Para escolher um modelo confiável e altamente disponível, precisa-se decidir com cuidado.
Se a taxa de eventos a ser administrada está dentro da capacidade de um único nó processador de stream, que é tipicamente maior que 50.000 eventos por segundo, recomendamos a seguinte implementação. Coloque os eventos de entrada em um intermediário de mensagens e então implemente dois nós de processamento de stream de forma ativa para consumir os eventos de um intermediário de mensagens usando um tópico. O processador de stream deve ser capaz de detectar falhas do nó ativo e trocá-lo.
Se a taxa de eventos está além da capacidade de um único nó processador de stream, deve-se colocar os eventos de entrada em um intermediário de mensagens e processar os eventos com o registro de dados num intervalo de tempo habilitado. Se uma falha ocorre, o processador de stream pode restaurar o estado usando tal registro e repetir eventos a partir deste ponto.
Características opcionais
A seção anterior apresentou as características essenciais que a maioria das aplicações de streaming precisam ter. Em contraste, segue uma lista das características opcionais que são necessárias apenas para algumas aplicações. Considere-as somente se sua aplicação realmente as necessita:
- Interfaces Gráficas de Usuários (GUIs) com recursos de arrastar e soltar mais amigáveis para usuários do negócio
- Streaming de dados para projetos de Aprendizado de Máquina
- Características opcionais de confiabilidade
- Garantia de processamento de mensagem
- Eventos fora de ordem
- Performance de sistema de larga escala
- Escalabilidade
- Lidar com grandes janelas
Devido a limitação de espaço, este artigo não apresenta as características opcionais, e os autores planejam cobrí-las em futuros artigos.
Conclusão
Por natureza, diferentes processadores de stream correspondem a diferentes casos de uso. Quando estiver tentando escolher o processador de stream que melhor lhe atende, você deverá considerar muitos aspectos para fazer a escolha certa.
Este artigo discute uma referência de arquitetura para processamento de stream e apresenta uma abordagem sistemática para a escolha de um processador de stream. A abordagem responde a duas questões principais. Primeiro, até que ponto o processador de stream suporta as características essenciais de um processador de stream? Segundo, quais são os requisitos especiais da aplicação e até que ponto tais requisitos são atendidos pelos processadores de stream candidatos? A primeira questão foi o foco deste artigo e a segunda será discutida em detalhes em artigos futuros. A figura 7 categoriza as características para formulação das respostas.

Figura 7: Categorização das características usadas para responder às duas questões chaves
O artigo discute cada característica essencial em detalhes e porque são importantes, ao mesmo tempo em que orienta sobre como escolher um processador de stream que melhor atende a natureza da aplicação.
Sobre os Autores
 Miyuru Dayarathna é um lider técnico na WSO2. Ele é um cientista da computação com múltiplos interesses em pesquisas e contribuições em processamento de stream, gestão e mineração de dados em grafos, computação em nuvem, engenharia de performance, IoT, etc. Ele também é consultor no Departamento de Ciência da Computação e Engenharia da Universidade de Moratuwa, Sri Lanka. Ele tem publicado artigos técnicos periódicos internacionais renomados e em conferências, além de organizar workshops internacionais sobre gerenciamento e processamento de dados em grafos em alta performance.
Miyuru Dayarathna é um lider técnico na WSO2. Ele é um cientista da computação com múltiplos interesses em pesquisas e contribuições em processamento de stream, gestão e mineração de dados em grafos, computação em nuvem, engenharia de performance, IoT, etc. Ele também é consultor no Departamento de Ciência da Computação e Engenharia da Universidade de Moratuwa, Sri Lanka. Ele tem publicado artigos técnicos periódicos internacionais renomados e em conferências, além de organizar workshops internacionais sobre gerenciamento e processamento de dados em grafos em alta performance.
 Srinath Perera é um cientista, arquiteto de software e programador que trabalha com sistemas distribuídos. Ele é membro da Fundação de Software Apache. Ele é um arquiteto-chave por trás de vários projetos usados amplamente, como Apache Axis2, Processador de Stream WSO2. Srinath escreveu dois livros sobre MapReduce e é autor frequente de artigos técnicos. Ele recebeu seu Ph.D da Universidade de Indiana, USA, em 2009. Ele está envolvido com o projeto de Serviços Web da Apache desde 2002 e é membro do comitê em vários projetos open source da Apache, incluindo Axis, Axis2, and Geronimo.
Srinath Perera é um cientista, arquiteto de software e programador que trabalha com sistemas distribuídos. Ele é membro da Fundação de Software Apache. Ele é um arquiteto-chave por trás de vários projetos usados amplamente, como Apache Axis2, Processador de Stream WSO2. Srinath escreveu dois livros sobre MapReduce e é autor frequente de artigos técnicos. Ele recebeu seu Ph.D da Universidade de Indiana, USA, em 2009. Ele está envolvido com o projeto de Serviços Web da Apache desde 2002 e é membro do comitê em vários projetos open source da Apache, incluindo Axis, Axis2, and Geronimo.