In a recent blog post, Google announced a few enhancements for Cloud Spanner - a globally distributed NewSQL database. Based on customer requests, Google updated the service with query introspection improvements, new region availability, and new multi-region configurations.
With Google Cloud Spanner customers can use a Cloud database service that combines the benefits of a relational database structure with non-relational horizontal scale. The service provides customers with high-performance transactions and strong consistency across rows, regions, and continents with a 99.999% availability SLA, no planned downtime, and enterprise-grade security. With an increase in availability in more regions, Cloud Spanner further improves performance as customers will have an option to host the database service in the same region as their application stack.
In the blog post, Deepti Srivastava, product manager, Cloud Spanner stated:
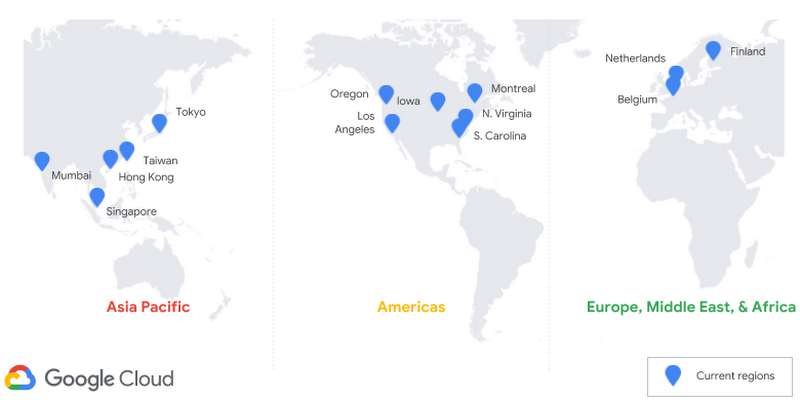
To help meet that goal, we recently announced the availability of Cloud Spanner in Hong Kong as part of the GCP region launch. Additionally, we have added Cloud Spanner availability to seven other GCP regions this year, bringing the total region availability to 14 (out of 18) GCP regions. New regions added this year are South Carolina, Singapore, Netherlands, Montreal, Mumbai, Northern Virginia, and Los Angeles. Our plan is for Cloud Spanner to be available in all new GCP regions moving forward.
Next, for more availability of Cloud Spanner in more regions, Google is also adding two new multi-region configurations. Multi-region configurations, GA since November of last year, provides customers with a more straightforward development model, improved availability, and reduced read latency. The new multi-region configurations are:
- nam6: multi-region coverage within the United States
- eur3: multi-region coverage within the European Union
Lastly, Google added a query introspection capability to provide customers with better visibility into frequent and expensive queries running on Cloud Spanner. They can, according to the blog post view, inspect, and debug the most common and most resource-consuming Cloud Spanner SQL queries that are executed on a database. Furthermore, Srivastava stated:
This information is useful both during schema and query design, as well as for production debugging—users can see which queries need to be optimized to improve performance and resource consumption. Optimizing queries that use significant amounts of database resources is a way to reduce operational costs and improve general system latencies.
For more details about the pricing of Cloud Spanner, see the pricing page.