In a recent blog post, Microsoft announced the 1.0 version of Kubernetes-based event-driven autoscaling (KEDA) component, an open-source project that can run in a Kubernetes cluster to provide fine-grained autoscaling (including to and from zero) for every pod and application. KEDA also serves as a Kubernetes Metrics Server and allows users to define autoscaling rules using a dedicated Kubernetes custom resource definition.
Jeff Hollan, principal PM manager, Azure Serverless, author of the blog post, told InfoQ:
KEDA is a key piece of our serverless story. KEDA and the open-sourced Azure Functions runtime provide serverless runtime and scale without any vendor lock-in. It allows enterprises to build hybrid serverless apps running across a fully managed cloud and the edge for the first time ever.
Earlier this year Microsoft announced KEDA in collaboration with Red Hat, which was well-received by users and the community. Hollan told InfoQ:
KEDA was possible because of collaboration with the community at large. Red Hat has contributed significantly to both the design and the code making KEDA work well on Open Shift. In addition, we’ve had dozens of contributors who have helped created new event sources, docs, samples, and features. The result is a tool that is better than any single organization could have created in isolation, and an open and collaborative pattern we feel is vital to bring forward.
Kubernetes is a container orchestrator, and is available on several cloud platforms as a managed service. By default, Kubernetes will only scale based on operational metrics like CPU and memory, and not in relation to application-level metrics such as thousands of messages on a queue awaiting processing. Therefore, developers need to define how their deployments need to scale by creating Horizontal Pod Autoscalers (HPA) – for which they will need to run a metric adapter to pull the metrics from the source that they want. In the case of multiple sources, it can become a challenge, and also requires more infrastructure.
However, with KEDA, Kubernetes can scale pod instances based on the knowledge of other metrics it pulls from a variety of sources. For example, it can pull information from a queue in order to learn how many messages are waiting for processing, and scale accordingly before the CPU load rises. The scaling occurs from 0 to n-instances of the application deployments, based on the configuration in the ScaledObject. Behind the scenes, KEDA adds HPAs when it needs to raise the instances of a deployment. If no instances are required, KEDA will delete the HPA.
Tom Kerkhove, Azure Architect at Codit and one of the main contributors on KEDA, told InfoQ:
You could already use HPAs with metric adapters but had to find out which ones you need and cannot run multiple adapters at the same time - KEDA fixes this by aggregating from various sources.
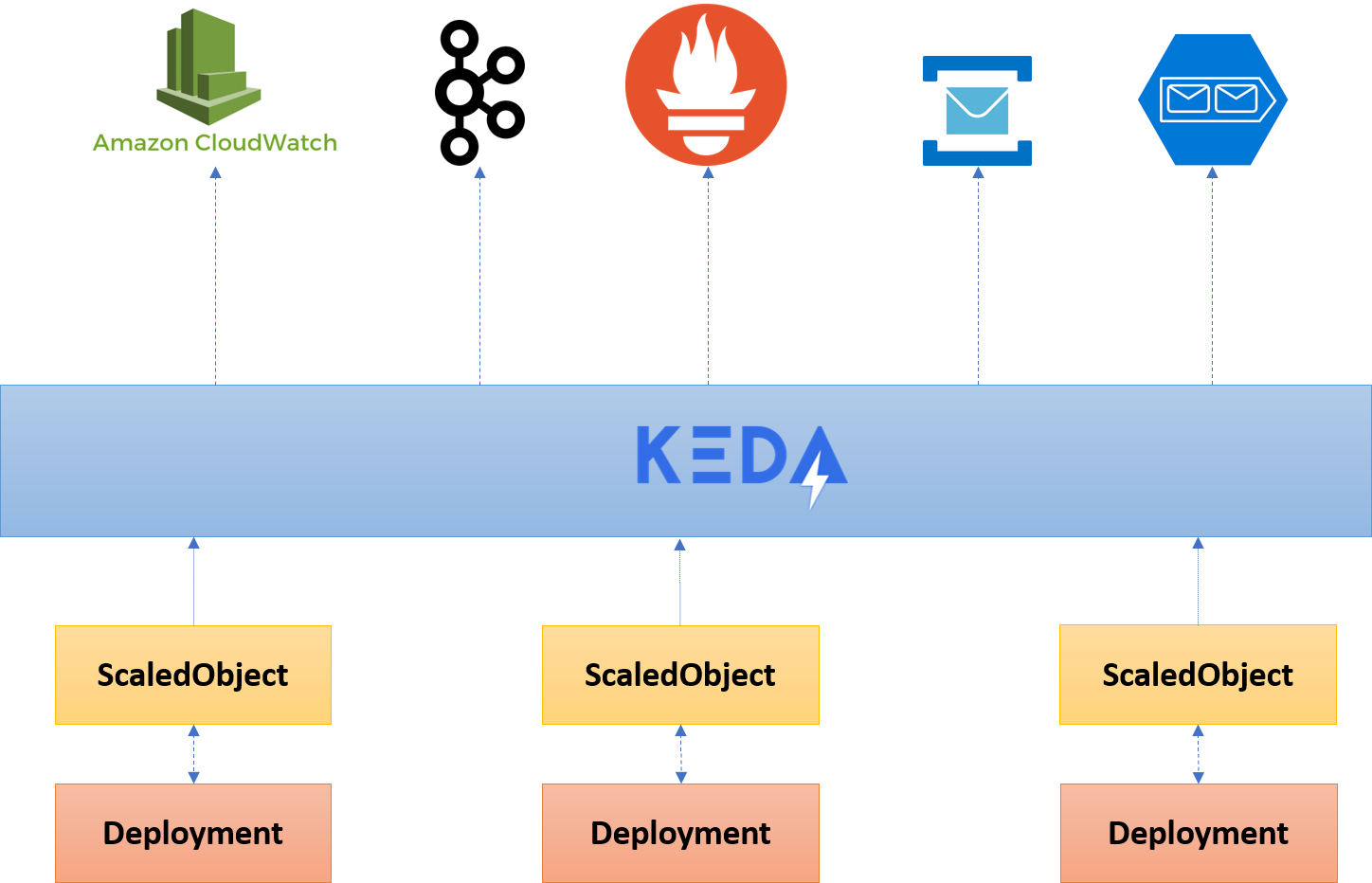
Source: https://blog.tomkerkhove.be/2019/11/19/keda-v1-autoscaling-made-simple/
Additionally, Kerkhove shared with InfoQ other benefits of leveraging KEDA:
- Another big win is that there was no official Azure Monitor metric adapter, other than James Sturtevant his OSS project or had to use Promitor via Prometheus & the Prometheus metrics adapter.
- TriggerAuthentication now provides production-grade authentication by supporting pod identities like Azure Managed Identity, allowing you to re-use authentication information. Next to that, you can decouple the assigned permissions on your application from what KEDA needs, which reduces the exposure risk.
- Deployments got a lot simpler with Helm 2.x & 3.0 and are available on hub.helm.sh. KEDA is now based on Operator SDK and will be in Operator Hub soon.
- It now supports scaling jobs instead of only deployments.
- It will be donated to CNCF to allow it to grow and to let other vendors jump in and help improve the product by adding more scalers, better usability, etc.
Developers can learn more about KEDA at KEDA.sh or try a step-by-step QuickStart.