Cloud Bigtable is a fully-managed, scalable NoSQL database service for large operational and analytical workloads on the Google Cloud Platform (GCP). And recently, the public cloud provider announced the general availability of Bigtable Autoscaling, which automatically adds or removes capacity in response to the changing demand for applications allowing cost optimizations.
Autoscaling for Bigtable automatically scales the number of nodes in a cluster up or down based on changing usage demands. As a result, it reduces the risk of over-provisioning and incurring unnecessary costs and under-provisioning, resulting in missed business opportunities.
Earlier, scaling of Bigtable could be done programmatically as Bigtable's Cloud Monitoring API exposes several metrics. A customer could programmatically monitor these metrics for a cluster and then add or remove nodes based on the current metrics using one of the Bigtable client libraries or the gcloud command-line tool.
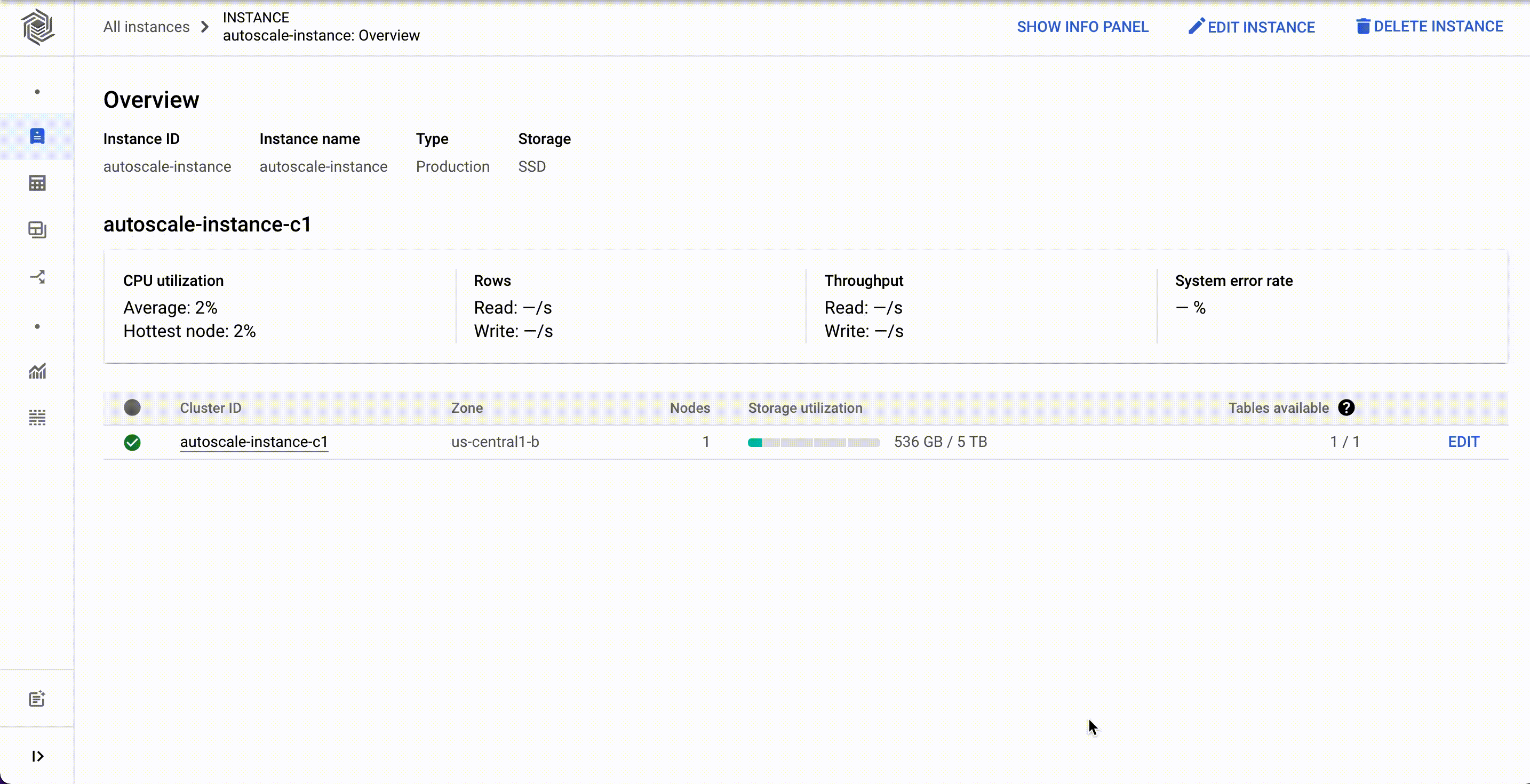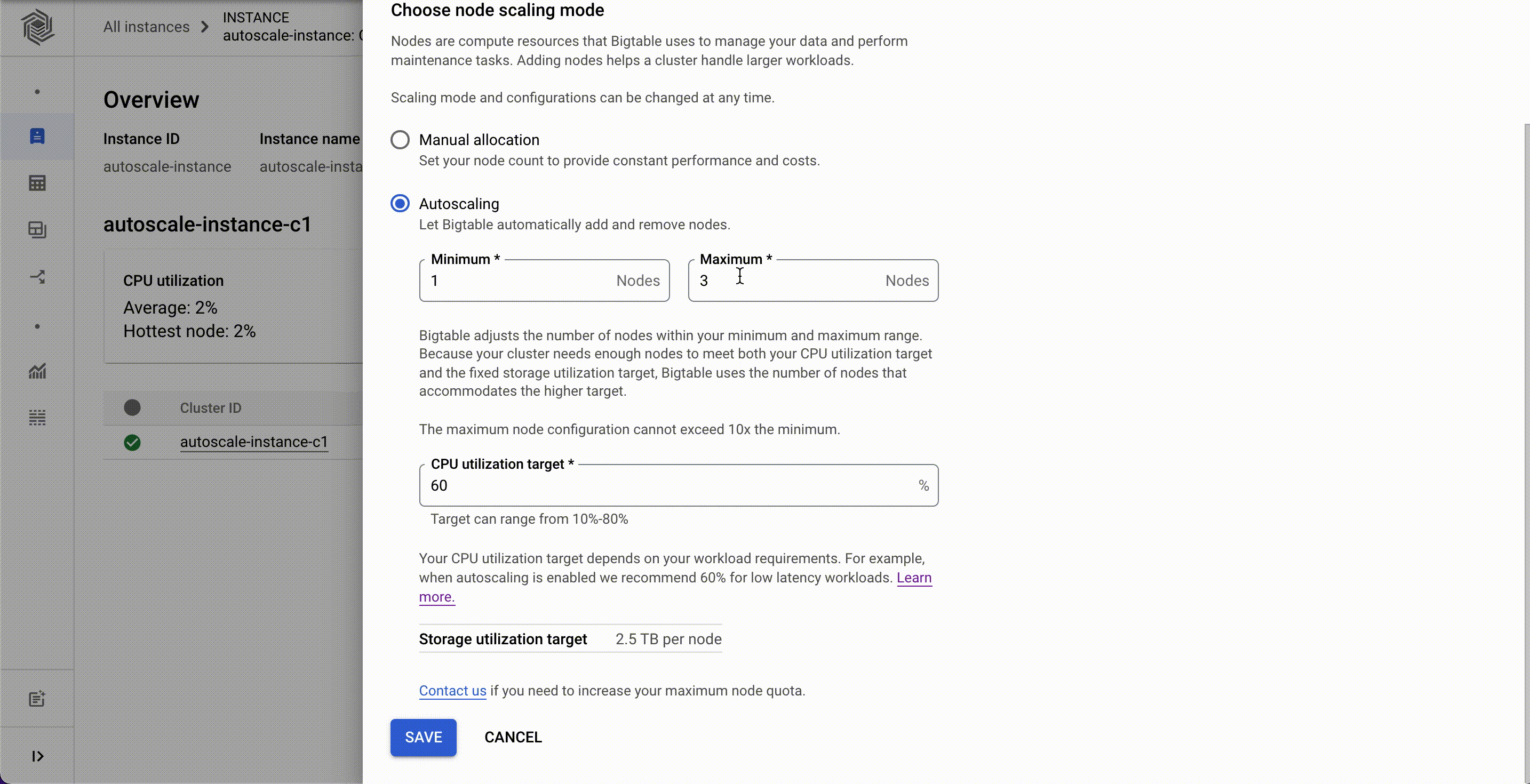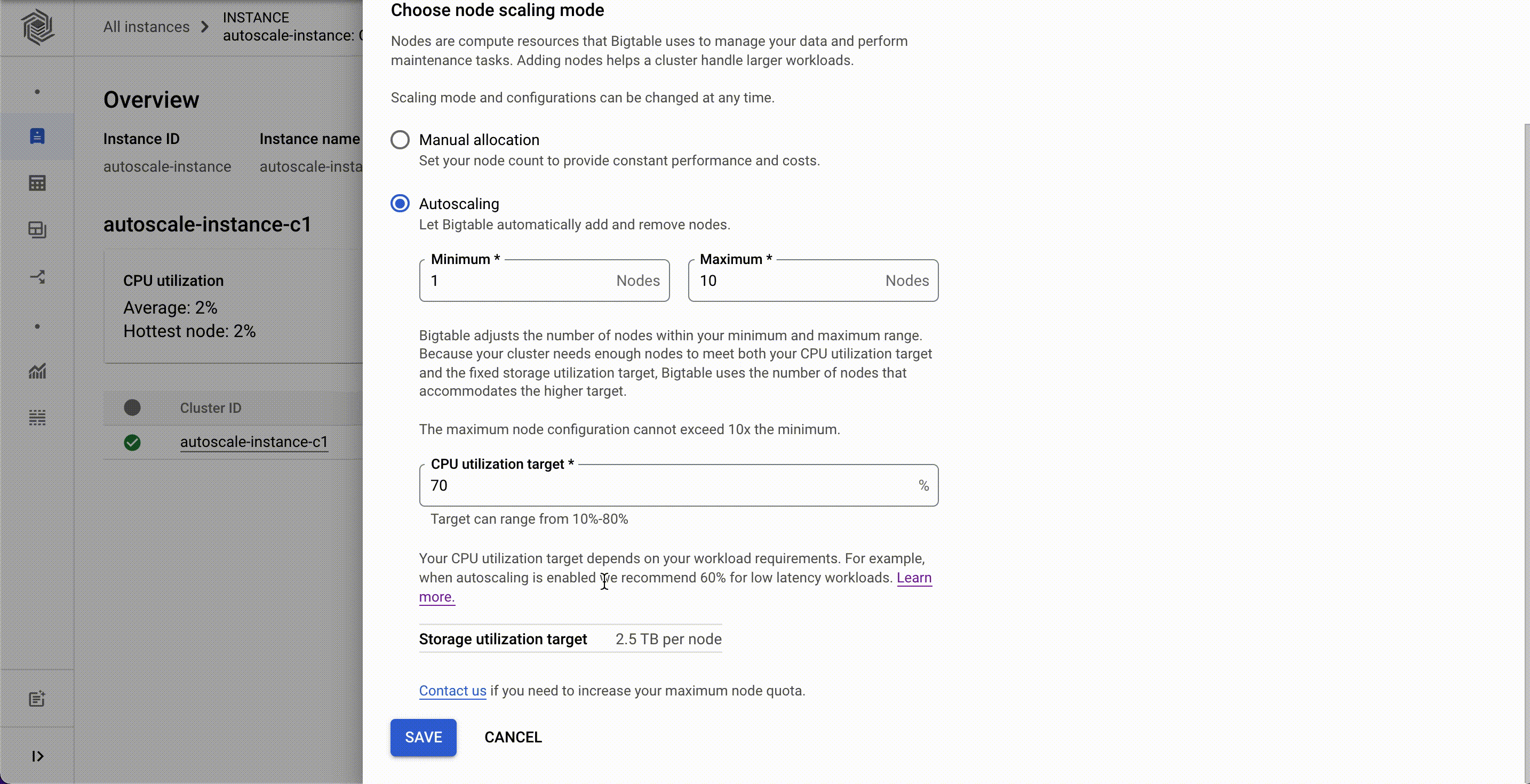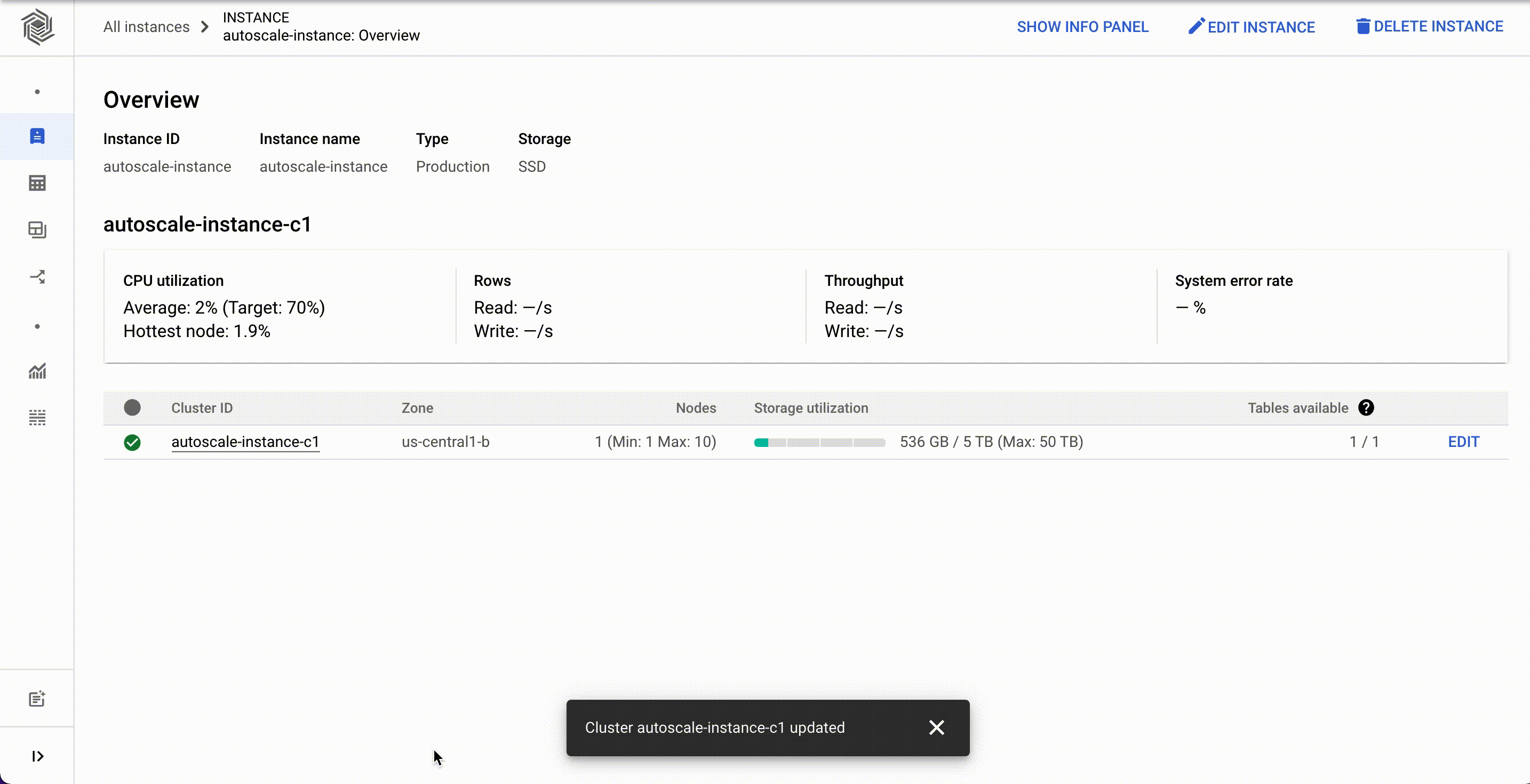
Now, customers can configure autoscaling for their Bigtable clusters via the Cloud Console, gcloud, the Bigtable admin API, or client libraries. They can set the minimum and the maximum number of nodes for their Bigtable autoscaling configuration instead of doing it programmatically.
In a deep-dive blog post on Bigtable Autoscaling, Billy Jacobson, a developer advocate Bigtable, and Justin Uang, a software engineer Bigtable, explained the enabling of the autoscaling feature:
Autoscaling can be enabled for existing clusters or configured with new clusters. You'll need two pieces of information: a target CPU utilization and a range to keep your node count within. No complex calculations, programming, or maintenance are required. One constraint to be aware of is the maximum node count in your range cannot be more than 10 times the minimum node count. Storage utilization is a factor in autoscaling, but the targets for storage utilization are set by Bigtable and not configurable.
In addition to Autoscaling, Google also added features to further optimize cost and reduce management overhead, such as:
- Double the storage amount to let customers store more data for less, particularly valuable for optimized storage workloads. Bigtable nodes now support 5TB per node (up from 2.5TB) for SSD and 16TB per node (up from 8TB) for HDD.
- Cluster groups provide flexibility for determining how customers can route their application traffic to ensure a better customer experience. For example, customers can deploy a Bigtable instance in up to 8 regions to place the data as close to the end-user as possible.
- More granular utilization metrics improve observability, faster troubleshooting, and workload management. For instance, the recent CPU utilization by app profile metric includes method and table dimensions, which provide more granular observability into the Bigtable cluster's CPU usage and how your Bigtable instance resources are used.
Lastly, the autoscaling feature is available in all Bigtable regions and works on HDD and SSD clusters.