Nexa AI unveiled Omnivision, a compact vision-language model tailored for edge devices. By significantly reducing image tokens from 729 to 81, Omnivision lowers latency and computational requirements while maintaining strong performance in tasks like visual question answering and image captioning. The model’s architecture integrates a Qwen-2.5-0.5B language backbone, a SigLIP-400M vision encoder, and an optimized projection layer to ensure seamless processing of multimodal inputs.
Omnivision’s architecture is designed for efficient multimodal processing, featuring three core components. The Qwen-2.5-0.5B model acts as the backbone for processing text inputs, while the SigLIP-400M vision encoder generates image embeddings from input images. This encoder operates at a resolution of 384 with a 14×14 patch size, optimizing visual data extraction. A projection layer then aligns the image embeddings with the token space of the language model using a Multi-Layer Perceptron (MLP), which allows for streamlined visual-language integration.

Source: Nexa AI Blog
A key innovation is its 9x reduction in image tokens, reducing processing requirements without compromising accuracy. For example, Omnivision can generate captions for high-resolution images in under two seconds on a MacBook M4 Pro, requiring less than 1 GB of RAM. To ensure accuracy and reliability, it uses Direct Preference Optimization (DPO), leveraging high-quality datasets to minimize hallucinations and enhance prediction trustworthiness.
The model's training pipeline is structured in three distinct stages. The pretraining phase focuses on aligning visual and textual inputs to establish foundational capabilities. Supervised fine-tuning follows, enhancing the model's ability to interpret context and generate relevant responses. Finally, Direct Preference Optimization (DPO) refines decision-making by minimizing inaccuracies and improving precision in context-specific outputs.
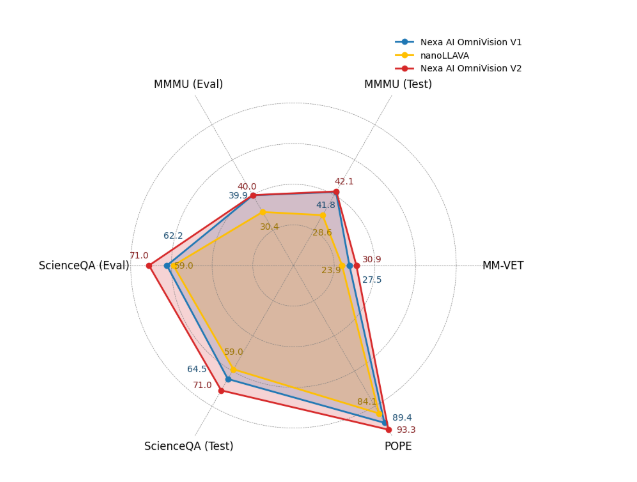
Omnivision has outperformed its predecessor, nanoLLAVA, in benchmark evaluations across datasets like ScienceQA, MM-VET, and POPE. It achieved notable improvements, including a 71.0% accuracy rate on ScienceQA test data and 93.3% accuracy on the POPE benchmark, demonstrating its reliability in complex reasoning tasks.
Source: Nexa AI Blog
Currently, Omnivision is focused on visual question answering and image captioning. However, Nexa AI revealed plans to expand the model’s capabilities to support optical character recognition (OCR). In a recent Reddit discussion, AzLy shared:
Currently, OCR is not one of this model's intended uses. It is mainly for visual question answering and image captioning. However, supporting better OCR is our next step.
Omnivision can be deployed locally using the Nexa-SDK, an open-source framework that supports a wide range of multimodal tasks. The model is still in early development, and the team is actively gathering feedback from users to guide future improvements.