Netflix has shed light on how the company uses the latest version of their Keystone Data Pipeline, a petabyte-scale real-time event stream processing system for business and product analytics.
Three major versions of the pipeline, now used by “almost every application at Netflix” can be summarized as follows:
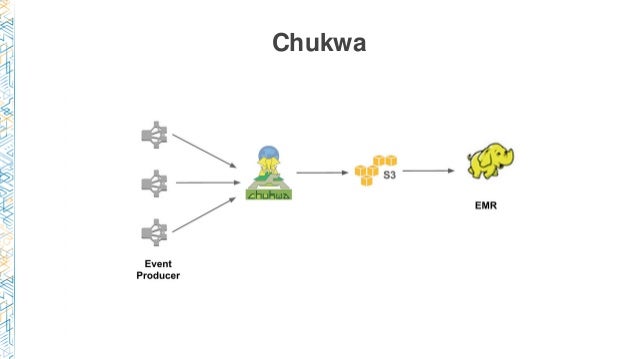
- A Chukwa to S3 based data ingest for later processing by Elastic Mapreduce (EMR).
- The same pipeline with a Kafka fronted branch supporting the S3 to EMR flow, as well as real time stream processing with tools like Druid and Elasticsearch via a new routing service.
- RESTful Kafka implementation streaming to a newer version of the routing service managed with a control plane, and then ingested by a consumer Kafka, Elasticsearch, or other stream consumers like Mantis or Spark.
{kind=link}
{kind=link}
{kind=link}
The version 1 end-to-end data transfer took a reported ten minutes. The batch pipeline used S3 as the persistent store and EMR for data processing. Chukwa is not replicated, making it sensitive to downstream sinks.
{kind=link}
Chukwa’s SocketTeeWriter allows for branching the pipeline to Kafka later in version 1.5, highlighting the earlier version of the pipeline’s extensibility and its ability to fork without impacting existing functionality.
Version 1.5 introduced a Kafka fronted branch, that streams to consumers, or to a routing service that filters and transfers events to additional Kafka streams or Elasticsearch. Steven Wu, real-time data infrastructure engineer at Netflix noted that:
We want separate routing jobs for different sinks (S3, ES, secondary Kafka) for isolation. Otherwise, one sink outage can affect the same routing job for other sinks. We have many ES and secondary Kafka clusters.
This led to “setting up one topic per event type/stream”, Wu added, for providing isolation and buffering against downstream sinks that could possibly impact upstream publishing services.
The new branch exposed 30 percent of their event traffic in real-time to Elasticsearch, other Kafka streams for transformation, or to Spark for general data processing needs. This enabled interactive data analysis in Python, Scala, and R in real time.
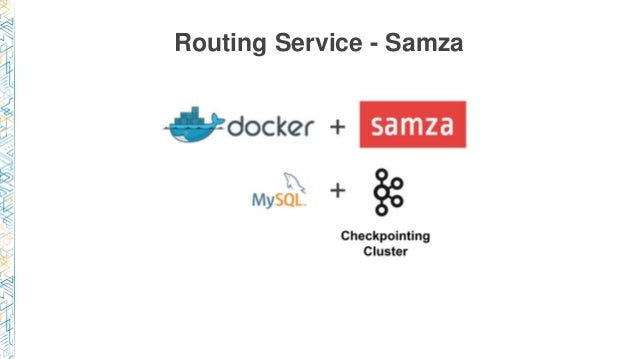
The routing service consists of multiple Docker containers running Samza jobs across EC2 instances. Separate EC2 fleets managed S3, Elasticsearch, and Kafka routes and generated container level performance monitoring data. Statistical summaries for latencies, lags and sinks were also generated for profiling the various parts of the pipeline.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
A number of learnings came out of the real time branch implementation, specifically around the Kafka fronted gate and the routing service. Wu noted that:
The Kafka high-level consumer can lose partition ownership and stop consuming some partitions after running stable for a while. This requires us to bounce the processes.
When we push out new code, sometimes the high-level consumer can get stuck in a bad state during rebalance.
The lessons from version 1.5 led to creating a pipeline with “three major components”, according to Netflix’s summary in Version 2.0. The first is an Ingest component accessible through a Java library that writes to Kafka directly and an HTTP proxy for languages like Python to post JSON to.
The second, buffering component includes Kafka as the persistent message queue, as well as the new control-plane service for managing the third component, a routing service. One of the contributing factors noted in the summary was that “the operational overhead of managing those jobs and clusters [was] an increasing burden”.
Netflix will provide more coverage on this topic as well as Kafka in cloud at scale, implementing a routing service using Samza and how they manage and deploy Docker containers for routing services.