はじめに
分散コンピューティングの考え方は誰もが知っている。タスクを複数のコンピュータで分割することで一台の中央コンピュータで全ての処理を行うより全体として処理能力を向上させることができるということだ。問題は多くの場合においてこのような仕組みを実際に実装するのがかなり複雑になることだ。
EJBのような技術はそのような実装を簡単にするだろうと思われていたが、いざ使ってみると設計と開発プロセスに干渉しすぎるものだった。幸いにも今はTerracotta(Terracotta)のようなJavaVMレベルのクラスタリング技術がメインストリームに登場したことで実用可能な選択肢がもたらされている。
最近Shine Technorogies社ではTerracotta(サイト・英語) を使ったアプリケーションを出したが、これは飛躍的にパフォーマンスを上げることに成功している。これまでアプリケーションのパフォーマンスは一般にそれが実行されているサーバの性能次第だった。Terracottaを用いればもはやこの制約は受けないですむ。私たちがパフォーマンステストをおこなっていた時、一台のサーバがリソースを使い切るケースがあった。主にリソースを消費していたのはデータベースだった。そんな時別のサーバを追加するだけでアプリケーション全体の処理能力を劇的に向上させることができた。
背景
Shine Technologiesは数多くのオーストラリアのエネルギー企業向けにITコンサルタントと開発のサービスを提供している。この業界のFull Retail Contestability(FRC)社で採用されたのを始めに、Shineはこれらの企業に対して多くの製品を開発してきた。
簡単にいえば、これらの製品は卸売業者と小売業者間の金銭的なやり取りをネットワークの点からサポートする。このやり取りの量は膨大で、大きな小売業者だと一月に数百万のトランザクションを処理することになる。そのためアプリケーションのスケーラビリティはビジネス上クリティカルな問題で、特に大きな小売業者から全てのトランザクションを一日に受ける時は重大である。
この製品群に最近新しく加わったアプリケーションは電力会社向けのサービス業者で使用されるものだ。このMarket Reconciliation System(MRS:市場照合システム)と呼ばれるアプリケーションは毎週多くの電気使用データを処理し、小売業者へのレポートと照合機能を提供するシステムで、電気使用に対する課金の見込と実際におこなっている課金との間の食い違いを明らかにする。
膨大なデータを扱う性質から、このアプリケーションのアーキテクチャにおいてスケーラビリティは重要な要素だった。最初の検証作業では様々なフレームワークを試したが、MRSの必要とする性能を一番与えてくれそうだったのがTerracottaだった。
TerracottaとMaster/Workerパターン
Terracottaはアプリケーションを複数のJVM上に分散させることが可能で、かつ同一のJVM上で動いてるかのようにアプリケーション間のやり取りをおこなうことができる。ユーザがJVM間で共有されることになるオブジェクトを指定することで、Terracottaは透過的にそのオブジェクトを全ての JVMからアクセス可能にする。Terracottaは特定のJEE(例えばTomcat(サイト・英語)やJBoss(サイト・英語)、Spring(サイト・英語)など)をクラスタリングできるように予め構成されたいくつものタイプが提供されている。しかし私たちのケースではアプリケーションコンテナを使わなかったので、自分たちでTerracotta の設定をする必要があった。
幸い私たちのアプリケーションに適用可能で、かつTerracottaとも相性がいいことが証明されていた方法を見つけていた。それが Master/Workerパターンだ。Terracottaでの使用が初めて言及されたのはJonas Boner氏の素晴らしいブログ記事How to Build a POJO-based Data Grid using Open Terracotta(source)だった。
Master/Worker を御存知でない方に説明すると、Masterは実行すべき作業アイテムを決め、各アイテムを共有キューに配置する役割を持つ。つづいて各アイテムの完了ステータスを監視し、全てが完了した時に自らの処理を終える。Workerは通常複数存在し、それぞれがキューの作業アイテムを取り出し処理をおこなう。処理が終わったらアイテムの完了ステータスをセットする。
私たちの実装ではMasterとWorkerの両方が別々のJVMで動作し、それらのJVMは多くのマシンに分散される。全ての共有オブジェクト(作業キューや作業アイテムのステータスなど)はTerracottaサーバによって管理され、また効率的に同期される。
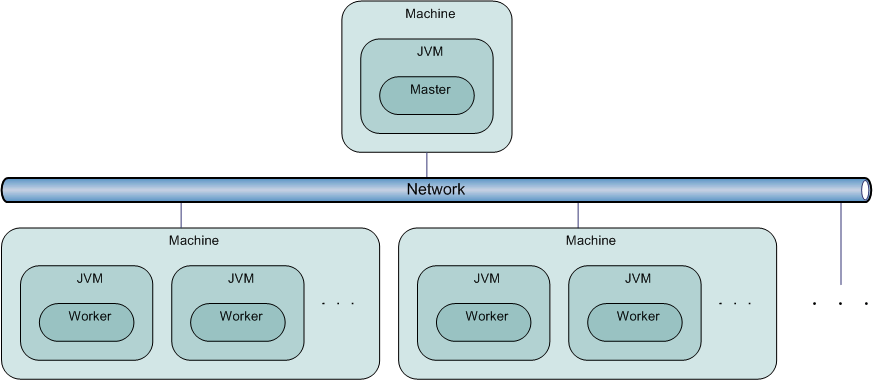
このアーキテクチャを視覚化するのに便利な方法はいくつかある。まず物理面だけを視覚化すると、ネットワーク上にあるマシン・JVM群・Master/Workerのセット間の関係はこのようになる。
{kind=link}

複数のJVMが一台のマシン上にあっても構わないことに注意してほしい。一つのJVMが利用可能な最大サイズのヒープ領域を使い切っている、しかしそのマシンの物理メモリには別のJVMが利用できるだけの空きがある、というような場合にはそうすることも可能だ。
ではTerracottaはこの物理的アーキテクチャのどこに該当するだろうか。Terracottaは全てのJVMを監視するため、より論理的な面を視覚化した以下の図が一番分かりやすいだろう。
{kind=link}

TerracottaはJVM群を有効に管理し、物理ネットワーク上で分散した作業アイテムのキューをJVMが透過的に共有することができるようにする。またTerracottaがMasterを追加することや、そのMasterともキューを共有させることも可能だ。
Terracottaを例で学ぶ
Terracottaでは分散性を考慮して具体的なコードを書く必要はないが、MasterとWorker間で共有されるデータを最小限に抑えるようにすれば結果として全体のパフォーマンスの向上につながるだろう。Workerが作業をより自立的におこなえるようになれば、 Terracottaサーバが複数のJVMにわたって管理するコストがより少なくなるのだ。
このことを考慮しながらシステムを開発するためにはある程度の試行錯誤があった。私たちが出会ったいくつかのハードルを説明するのに、簡単な例を挙げよう。
私たちのアプリケーションではカンマ区切り(CSV)データを格納した複数のファイルを処理する。そしてCSVデータの各行にはMaximum Daily Usage(MDU:一日最大使用量)と呼ばれるデータが含まれている。ここでは問題を簡単にするため、各ファイルの中で最大のMDUを知らせることを第一の目的としよう(実際の処理はこれよりはるかに複雑である)。
まず、Jonas Boner氏のブログ記事(source)にあるように、CommonJ(IBMとBEAの共同仕様)のWorkManager仕様(source)にあるWorkインターフェイスを実装したWorkUnitクラスを作ろう。このWorkUnitクラスが与えられたファイルの中から最大MDUを見つける役割を担い、コードはこのようになる。
public class WorkUnit implements Work
{
private String filePath;
private Reader reader;
public WorkUnit(String aFilePath)
{
filePath = aFilePath;
}
public void run()
{
private String maxMDU = "";
setReader(new BufferedReader(new FileReader(filePath)));
String record = reader.readLine();
while (record != null)
{
String[] fields = record.split(",");
String mdu = fields[staging:4];
if (mdu.compareTo(maxMDU) > 0)
{
setMaxMDU(mdu);
}
record = reader.readLine();
}
System.out.println("maximum MDU = " + maxMDU);
doStuffWithReader();
doMoreStuffWithReader();
doEvenMoreStuffWithReader();
}
private void setReader(Reader reader)
{
this.reader = reader;
}
... }
Masterは与えられたディレクトリ内にある各ファイルのパスをWorkUnit生成時に渡し、生成されたWorkUnitがそのファイルについて処理をおこなうことになる。またWorkUnitはステータスフラグを持ったWorkItemでラップされ、それが共有キューに入れられることで”スケジューリング”される。WorkerがこのWorkItemを取り出し、そのWorkUnitのrun()メソッドを呼び出す。それにより WorkUnitはファイルを処理して見つけた最大MDUを知らせる。この後でWorkUnitはこのファイルについての他のタスクに取り掛かることになる。
ここで一番注意してほしいのが、Readerクラスをインスタンス変数として持つようにしたことだ。Readerはいろいろなメソッドで使われるため、これをローカル変数で持って各メソッドに渡して回るのは実際には賢い方法ではない。
次に、Worker間でキューを共有するため、Terracottaのtc-config.xmlを次のように設定する。:
<application>
<dso>
<roots>
<root>
<field-name>
com.shinetech.mrs.batch.core.queue.SingleWorkQueue.m_workQueue
</field-name>
</root>
</roots>
<locks>
<autolock>
<method-expression>* *..*.*(..)</method-expression>
<lock-level>write</lock-level>
</autolock>
</locks>
<instrumented-classes>
<include>
<class-expression>
com.shinetech.mrs.batch.core.queue..*
</class-expression></include> <include>
<class-expression>
com.shinetech.mrs.batch.input.workunit..*
</class-expression>
</include>
</instrumented-classes>
</dso>
</application>
これについて詳細を理解する必要はない。ただ共有されるメンバ変数を指定していること(この場合キュー)と、それを安全に共有するにはどのクラスがが管理されればいいかを指定していることを理解してほしい。
私たちが最初にこのWorkUnitを使った結果は失敗に終わった。WorkUnitがReader変数の値をセットしようとした時、TerracottaからUnlockedShareObjectExceptionという例外がスローされたのだ。そのエラーメッセージには”共有ロックスコープ外の共有オブジェクトにアクセスしようとしました"とあった。Terracottaが言っていることはつまりMasterと Workerで共有されるオブジェクトの属性をを変更しようとしたということなのだが、私たちはTerracottaにそのオブジェクトの属性をロックする(あるいは同期する)ような指示をしていたわけではなかった。
この場合の一番の原因は、Workerが実行されるまでそのReaderインスタンス変数を初期化していないにもかかわらず、その変数は共有キューに入っているオブジェクトに属しているためTerracotta がMasterとWorkerで共有されている変数だと見なしたことにあった。(ちなみにTerracottaの例外処理は素晴らしいものだ。もし本来できないことをしようとした時、Terracottaは何が間違っているのかとそれを解決するために何をしたらいいのかを教えてくれるのだ。)
この段階で私たちが採れるアプローチはいくつかあった。一つは同期して呼ばれるsetReader()メソッドをWorkUnitクラスに持たせることだった。Terracottaはtc-config.xml内の自動ロック設定によってこのReaderインスタンスへのアクセスをロックすることになる。別の方法としてはコードを変更しないで、単にtc-config.xml内のロック設定部分に名前付けしたロック設定を加えることだった。それによりJVM クラスタ全体でこのReaderインスタンスへのアクセスが有効に同期されるようになる。
しかし結局のところどちらのアプローチも私たちが求めていたものではなかった。より現実的でより複雑なケースでは、Workerによって実行されているWorkUnitは読み取り専用のインスタンス変数を数多く持つことになるだろう。Masterはそれらのインスタンス変数について知る必要はなく、インスタンス変数もrun()メソッドの実行中にだけ存在していればいい。パフォーマンスの観点から、私たちはMasterがこれらWorkUnit属性にアクセスする必要がないのならTerracottaにそれらへのアクセスを同期させる必要はないと考えた。<named-lock>
<lock-name>WorkUnitSetterLock</lock-name>
<method-expression>
* com.shinetech.mrs.batch.dataholder..*.set*(..)
</method-expression>
<lock-level>write</lock-level>
</named-lock>
私たちが必要としたのはWorkUnitがMasterによってインスタンス化されるのではなく、WorkerがWorkItemをキューから取り出した時にインスタンス化される方法だった。これを行うために私たちはWorkUnitGeneratorというクラスを導入した。:
public class WorkUnitGenerator implements Work
{
private String filePath;
public WorkUnitGenerator(String aFilePath)
{
filePath = aFilePath;
}
public void run()
{
WorkUnit workUnit = new WorkUnit(filePath);
workUnit.run();
}
}
Master はWorkUnitGeneratorを生成し、それに処理するファイルのパスをあたえることになる。そしてWorkUnitGeneratorが WorkItemをラップしスケジューリングする。WorkerはWorkItemを取り出し、そのWorkUnitGeneratorのrun()メソッドを呼び出す。さらにrun()メソッドで新しいWorkUnitをインスタンス化し、ファイル処理はWorkUnitのrun()メソッドに任せる。これで私たちの望んだようにMasterから切り離されるべきWorkUnitがその通り実現し、TerracottaはJVM間の不必要な同期をおこなわなくてもよくなった。
上でアウトラインを示したサンプルコードはMaster/Workerパターンに対するアプローチの一つでしかない。他にもいろいろなやり方があるだろうし、よりTerracottaを用いた経験を重ねた後になれば、もっと良い実装方法を見つけられるかもしれない。大事なのはTerracottaとMaster/Workerパターンの組み合わせは複数のマシンで分散処理を行えるようにしてくれるが、何を共有して何を共有しないかについては慎重にならないといけないということだ。
パフォーマンス結果
検証作業ではTerracottaはかなり期待できそうだったが、果たして実際そうなったのか。アプリケーションのスケーラビリティをテストする計画が立てられた。872,998件のデータが格納された89のデータファイルが使われたが、これは実際の製品システムから持ってきたもので、現実的なデータを扱っていることは私たちの自信となった。
Terracottaサーバと単一のMasterプロセスは一台のマシン上で動く。そして数量不定の分散Workerマシンがデータの処理を行い、各マシンでは4つのWorkerを動かす。その結果は以下のようになった。:
| Workerマシン数 | Worker数 | 時間(秒) |
| 1 | 4 | 416 |
| 2 | 8 | 261 |
| 3 | 12 | 214 |
| 4 | 16 | 194 |
| 5 | 20 | 193 |
グラフにすると以下のようになる。:

4 つのWorkerが動く1台のWorkerマシンだけでは89ファイルを取り込むのにトータルで416秒かかった。この分散コンピューティングシステムにもう一台のWorekerマシンを加えただけで89ファイルの取り込み時間はほぼ半分になった。新しいWorkerマシンを加えるごとにさらにパフォーマンスの向上を得ることもできた。
ただ上のグラフに見られるように、スケーラビリティは頭打ちを始める。さらにWokerを加えてもデータベースサーバが増大した負荷を受けることになり、それがいずれある時点で十中八九ボトルネックになるだろう。
結論
Jonas Boner氏のTerracottaとMaster/Workerパターンを使った方法を拡張して、私たちはアプリケーション向けの分散コンピューティングコンポーネントを作ることができた。
現在私たちのアプリケーションは顧客の本番環境で稼動しているが、今のところデータ処理には一台のマシンしか必要としていない。しかし他の本番環境から持ってきたより大きなデータを使い、数台のマシンに分散処理させるパフォーマンステストを行った結果、必要になればTerracottaによってアプリケーションをスケーリングする自信が得られた。
結局のところデータベースがボトルネックだと分かったが、分散処理させて得られるパフォーマンスがあれば許容できるレベルだ。ただCPU割り込みをおこなうプロセスを実行しているケースではスケーラビリティが向上するかは分からないが。
現在私たちのアーキテクチャではMaster(つまり処理されるタスクを作り出すプロセス)がTerracottaと同一マシンの上で動いているが、いずれ今のMasterマシンにとって過負荷になるはずだから、その時は負荷分散のために別のMasterマシンを追加しないといけないのがちょっとした課題だ。
Terracottaは私たちのアプリケーションが必要とした要求のある部分を満たしてくれた。私たちは今、追加される現実のデータでどれだけのパフォーマンスがあるかをこれから数ヶ月にわたり観察し続けること、そして今回の私たちの経験が我が社の他のアプリケーションにどれだけ利益をもたらすかを楽しみにしているところだ。
この記事は http://www.shinetech.com (英語) の好意により提供された。
原文はこちらです:http://www.infoq.com/articles/master-worker-terracotta(このArticleは2008年2月5日に原文が掲載されました)