昨年の終わり頃にGoogleが同社の機械学習ライブラリである TensorFlow をオープンソースするという 発表を行い、 InfoQが取材をして以来、 データサイエンスコミュニティは各々のプロジェクトでTensorFlowを試す機会を得た。
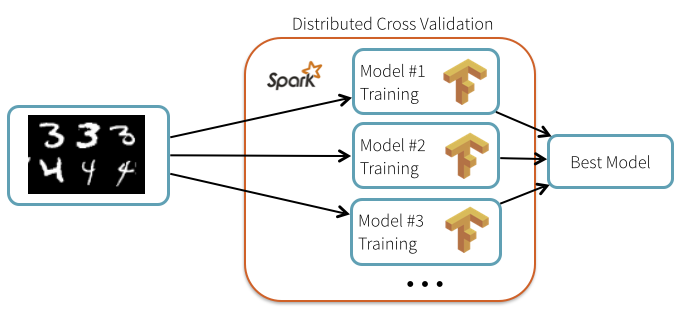
Databricks社 のTim Hunter氏は、Sparkを使って行うTensorFlowが生成するモデルの選択や、 大規模なニューラルネットワーク処理を紹介する。
Hunter 氏は、人工ニューラルネットワーク とは脳の視覚野にあるニューロンを模倣しているもので、これを適度に訓練すると複雑なイメージや音声データを処理できるようになると解説する。
Hunter 氏はさらに、様々なSparkの設定で TensorFlow を実行し、 どのようにしてハイパーパラメタの最適化を並列に処理したかを詳細に説明する。 Hunter 氏は、 Python と C++が現在サポートされている TensorFlowが、“様々なタイプやサイズのニューラルネットワークの訓練アルゴリズム生成を自動化する助けになった”という。ここでの目的は、大量のデータを高い正確度で最適化された性能で処理するニューラルネットワークを訓練することである。
{kind=link}
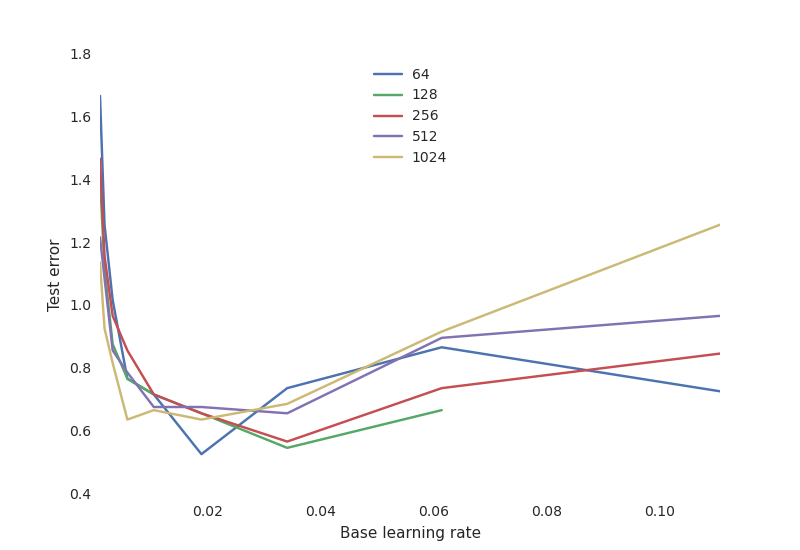
Hunter氏が紹介したハイパーパラメタには、各層のニューロン数や学習率がある。これらのパラメータは、ニューラルネットワーク自体に適用される訓練アルゴリズムとは別に決められる。
使用するアルゴリズムに対してハイパーパラメタがどれだけうまく調整されているかが、訓練にかかる時間やモデルの正確度に影響を与える。各ハイパーパラメタの値は 相関 変数と対比される。例えば各層のニューロン数とテスト誤差である。Hunter 氏は次のように述べている
{kind=link}
学習率は非常に重要です。もし値が小さすぎるとニューラルネットワークは何も学習しません(高い学習誤差)。反対に値が大きすぎると訓練プロセスは大きく振れて、設定次第では発散してしまうでしょう。
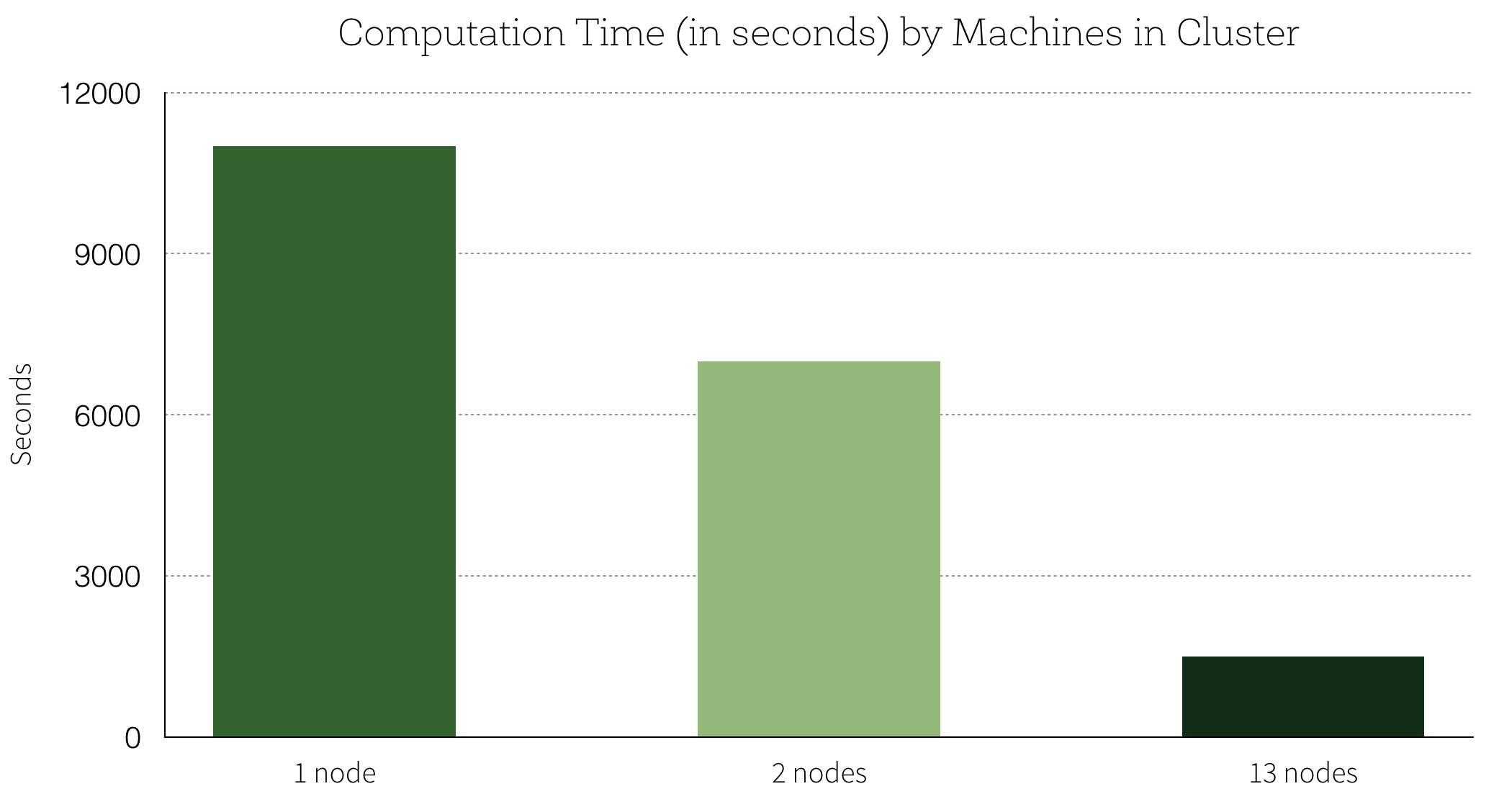
DatabricksはSpark上のTensorFlow訓練アルゴリズムが、正確度と実行時間に与える影響を計測する実験をした。この実験で使用されたのは、デフォルトのハイパーパラメタ、ハイパーパラメタの幾通りかの設定、訓練データ、クラスタサーバである。クラスタには、シングルノード,2ノード,13ノードのSparkクラスタが用意された。
最適なハイパーパラメタを見つけるため、Hunter氏はSparkで分散 処理して、TensorFlowが生成したモデルの有効性検証を並列に行った。
Hunter氏は、Sparkを使うことで
データやモデルなど共通の要素を配信し、それぞれの反復計算をクラスタ全体でスケジュールするので障害に強い実行環境が得られます。
Hunter氏はモデルの正確度の改善とSparkを用いた実行時間について
{kind=link}
たとえニューラルネットワークのフレームワークが一つのノードでしか実行できなくても、Sparkを使ってハイパーパラメタの最適化やモデルの展開を分散して処理することができます。
アルゴリズム選択を分散して処理することで訓練時間が短縮でき、標準のハイパーパラメタと比較して正確度は34 パーセント 改善された。さらに、 Databricks は各ハイパーパラメータがどれだけ影響を受けやすいかをよりよく知ることができた。
TensorFlowが生成する複数のアルゴリズムを並列に、あるいはHunter氏のいう“あきれるくらいの平行処理” で処理して比較すると、シングルノードに比べて、モデルの検証が 7倍 高速化した。
一旦最適なモデルが選ばれて訓練されると、ニューラルネットワークはSparkに配置されて大きなデータに対して実行できるようになる。
Databricks は特定のハードウェアについて言及していないが、実験を再現し、さらにDatabricksのクラスタのオプション を知るためにHunter氏が用意したiPythonノートブックからある程度推察することができる。
クラウドや平行処理の環境がますます増え、広くエンジニアに使われている現状において、SparkやTensorFlowなどを使ってモデル選択やニューラルネットワークの訓練をスケールさせるのは、データサイエンスや機械学習コミュニティのかねてからの願いだった。
Rate this Article
- Editor Review
- Chief Editor Action