先日のブログ記事でGoogleは、NVIDIA Ampere A100 Tensor Core GPUをベースとした、Accelerator-Optimized VM(A2)ファミリをGoogle Compute Engineに導入することを発表した。A2は単一VMで最大16GPUを提供する、パブリッククラウドとしては初のA100ベースのサービスである。
GoogleのA2ファミリVMは、トレーニングや推論に関するカスタマのコンピュータパフォーマンス向上を目的にデザインされた。A2は、NVIDIA Ampereアーキテクチャに基づいて新たに開発された、NVIDIA A-100 Tensor Coreグラフィックプロセッサを装備し、ブログ記事によれば、前世代のGPUとの比較で最大20倍の計算能力と、40GBのハイパフォーマンスHBM2 GPUメモリを提供する。さらにA2 VMには、最大96のIntel Cascade LakevCPU、オプションとしてGPUにより高速なデータフィードを行うワークロード用のローカルSSD、最大100Gbpsのネットワークが提供される。
さらに厳しい要件を抱えるカスタマのために、A2には、16台のA100 GPUで構成されるa2-megagpu-16gインスタンスが用意されている。これは、合計640GBのGPUメモリ、1.3TBのシステムメモリ、最大9.6TB/秒の統合帯域を持つNVSwitchによる全体接続を備える。
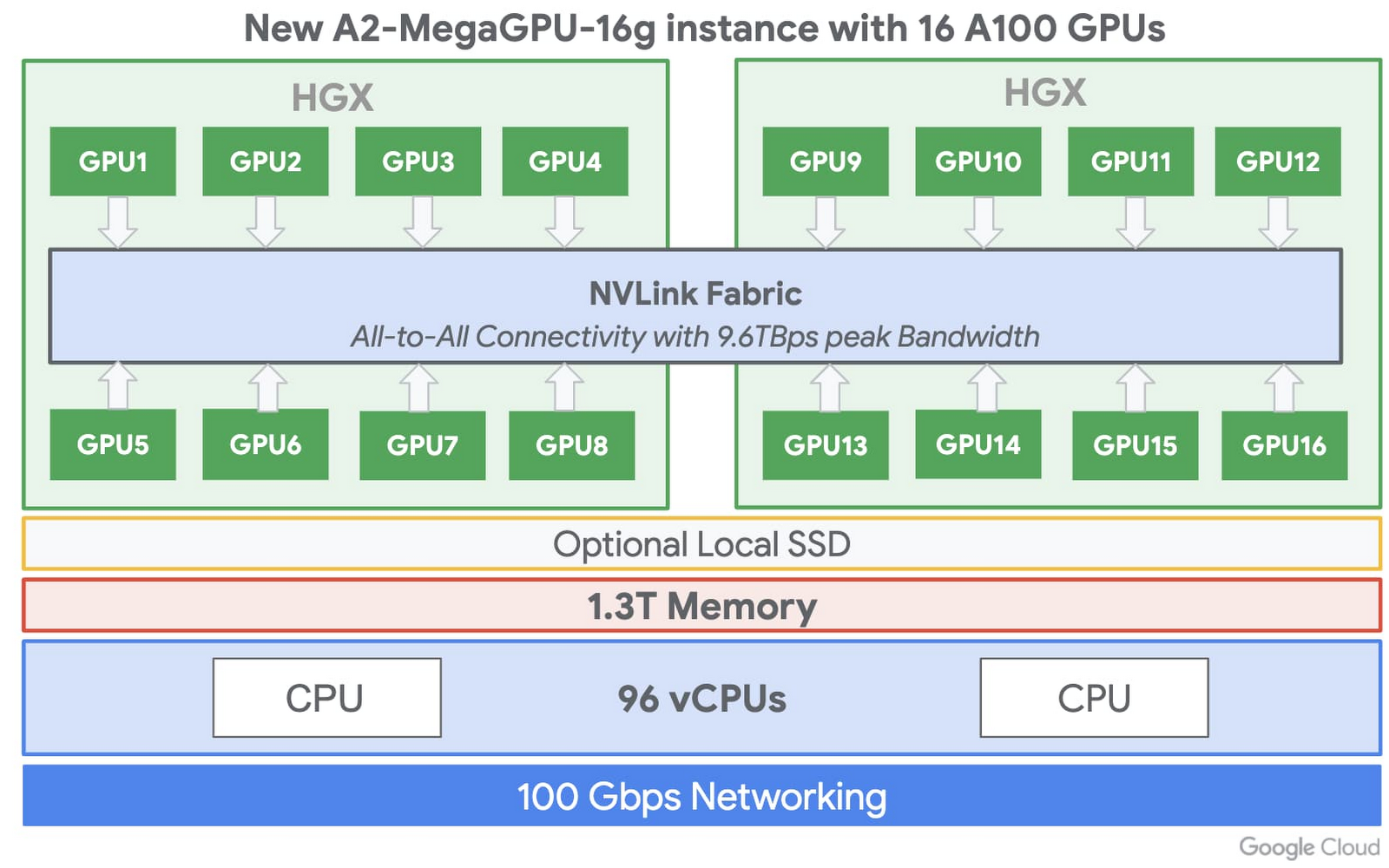
カスタマのGPU計算能力へのニーズによりマッチするように、もっと小さなコンフィギュレーションも用意されており、1~16のGPU、2種類のCPU、GPUへのネットワークレシオによる、5つのコンフィギュレーションから選択することができる。 さらに個々のGPUは、Ampereのマルチインスタンスグループ(MIG)機能を使用することによって、最大7つのGPUインスタンスに分割することも可能だ。
NVIDIAでAccelerated Computingを担当する、ジェネラルマネージャでVPのIan Buck氏は先日、同社のブログ記事に、GCPでのA-100提供について書いている。
クラウドデータセンタでのA100は、AIのトレーニングや推論、データ分析、化学計算、ゲノム分析、最先端の画像分析、5Gサービスなど、広範な計算集中型アプリケーションを支援することが可能です。
A2ファミリの導入によってGoogleは、一般的な計算処理からアクセラレータ最適化マシンまで、同社の定義済VMとカスタムVMのポートフォリオをさらに拡大し、先頃Intelチップセット(AVX-512)で動作する、汎用目的かつメモリ最適化されたVMファミリを新たにリリースしたMicrosoftや、InferentiaチップベースのEC2 Inf1インスタンスをリリースしたAWSなど、他クラウドベンダとの競合を続けていく。これら新タイプのVMの多くは、AIやマシンラーニングに関するワークロードを持つカスタマを対象としたものだ。
Constellation Research Inc.のプリンシパルアナリストでVPのHolger Mueller氏は、次のように語っている。
クラウドのリーダシップをめぐる争いの中心はAI戦争です。これは企業のAIロードを、それぞれのベンダのクラウドに引き寄せるための戦いなのです。その中心にあるのは、クロスクラウドプラットフォームとオンプレミスオプションを提供する、NVidiaのようなプラットフォームベンダです。ですから、GoogleがNVidiaの最新プラットフォームを導入することによって、企業幹部(CxO)はAIワークロードをオンプレミス間や(Google)クラウドへ、簡単に移動できるようになるのです。
さらに氏は言う。
3番手のベンダであるGoogleは、ワークロードを引き寄せるために、よりオープンで、よりクリエイティブでなければなりません — そしてこれは、Googleの戦略のもうひとつの例なのです。対象的に、上位ベンダであるAWSとAzureの戦略は、依然としてAIロードを独自のクラウドコンピューティングアーキテクチャへ移行しようとするものです。ユーザ企業の幹部は、大部分のテクノロジベンダが依然としてロックインを望んでいることを認識し、便利さや速度とロックインの間にあるリスクのバランスを取らなくてはなりません。
現時点ではA2 VMファミリはアルファ版であり、サインアップによってアクセスを要求することができる。さらにGoogleは、一般公開と価格情報を年内に提供予定であると述べるとともに、Google Kubernetes Engine、Cloud AI Platformなど他のサービスでもNvidia A100をサポートする予定である、としている。