Google Cloud Dataflowは、Google Cloud Platform(GCP)内でApache Beamパイプラインを実行するための、完全マネージドなサービスである。先日のブログ記事でGoogleは、Runner v2 to Dataflowという、これまでよりもサービスベースのアーキテクチャを新たに発表した。言語SDKのすべてを対象とする多言語サポートも含まれる。
セカンドバージョンとして再設計されたApache BeamのDataflowランナでは、次のものが提供される。
- 複数言語サポート
- Pythonのステータスとタイマのサポートを含む、SDK全体を通じた等価性の向上
- Kafka I/Oなどのクロス言語フレームワークを使うことにより、さらなるI/Oをpython開発者に提供
- カスタムコンテナのサポート
- SplittableDoFnsを使用したスループット向上
- パフォーマンス向上
複数言語サポートでは、開発チームがそれぞれ選択した言語で記述したコンポーネントを組織内で共有し、単一のハイパフォーマンスな分散処理パイプラインに統合することが可能になる、とGoogleのブログ記事には述べられている。Runnerのセカンドバージョンまで、これは不可能だった。
Runner V2 has a more efficient and portable worker architecture rewritten in C++, which is based on Apache Beam's new portability framework. さらにGoogleは、このフレームワークを、バッチジョブ用のDataflow Shuffle、ストリーミングジョブ用のStreaming Engineとパッケージにすることで、言語用SDKすべてに共通の標準機能セットを提供すると同時に、バグ修正やパフォーマンス改善を共通化している。アーキテクチャ内で最も重要なコンポーネントは、パイプライン全体の実行と各SDKへのアクセスを行うワーカVM(Virtual Machine)だ。
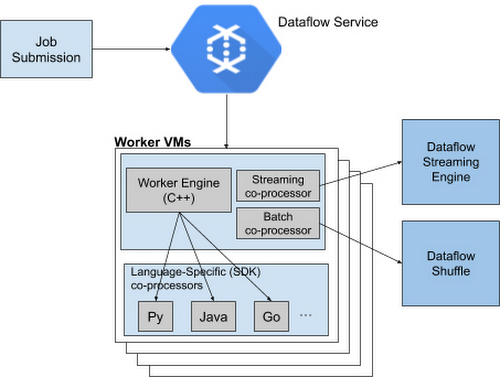
ブログ記事では、GoogleのソフトウェアエンジニアであるHarsh Vardhan、Chamrikara Jayalath両氏が次のように書いている。
機能や変換の不足している言語があるならば、SDK間で複製して同一性を確保する必要があります。そうでなければ、機能のカバレッジにギャップが生じて、Apache Beam Go SDKのような新しいSDKほど機能が少なかったり、特定のシナリオでパフォーマンス特性が劣ったりする可能性が生じます。
現時点では、Dataflow Runner v2はPythonストリーミングパイプラインで使用することができる。Googleはこの新しいRunnerを、すべての新パイプラインのデフォルトとして有効にする前に、現在の非運用系パイプラインでテストするように推奨している。さらに、公開中のチュートリアルを使用すれば、Dataflow PythonパイプラインからKafkaのトピックにアクセスすることも可能だ。最後に、資料によると、課金モデルはまだ決定していないということである。