Microsoft Researchは最近、画像エンコーディング用の新しいオブジェクト属性検出モデルを開発した。これは、VinVL (Visual features in Vision-Language)と名付けられた。
見ている画像を理解し、聞いている音を解釈する人間の能力を模倣するために、人工知能(AI)の研究者は、コンピューターに同じスキルを持たせようとしている。これらのスキルは、周囲の世界を効果的に理解するためにコンピューターに視覚言語を提供することで可能になる。たとえば、視覚言語(VL)システムでは、関連する画像でテキストクエリを検索し(またはその逆)、自然言語を使用して画像のコンテンツを記述することができる。このようなシステムは、次の2つのモジュールで構成される。
- 入力画像の特徴マップを生成するための画像エンコーディングモジュール
- エンコードされた画像とテキストを同じセマンティック空間内のベクトルにマッピングする視覚言語融合モジュール。これにより、ベクトルのコサイン距離を使用して意味的類似性を計算できる。
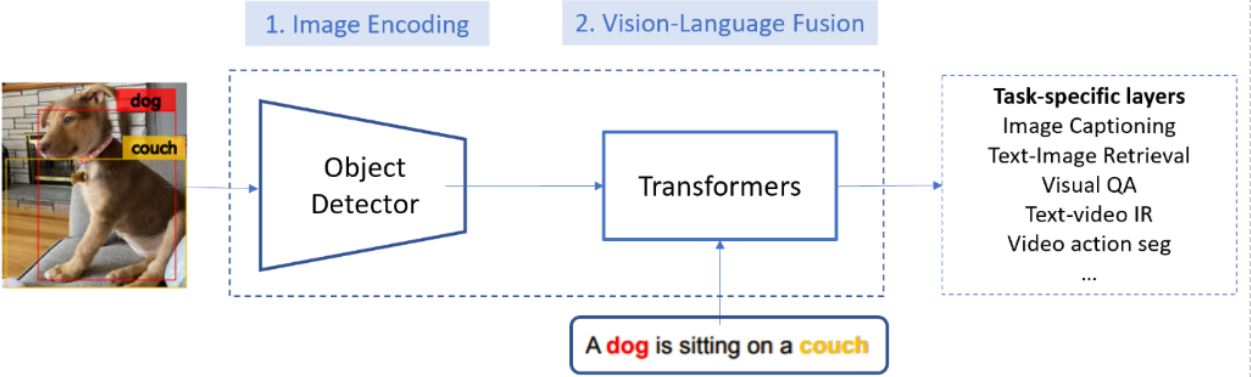
Microsoftの研究者は、VinVLを開発することにより、画像エンコーディングモジュールの改善に取り組んだ。OSCARやVIVOなどのVLフュージョンモジュールをVinVLと組み合わせることにより、Microsoft VLシステムは、7つの主要なVLベンチマークすべてにおいて最高値を記録している。VinVLに関するMicrosoft Researchのブログ投稿によると、VLシステムは最も競争力のあるVLリーダーボードでトップの位置を獲得した。リーダーボードには、ビジュアル質問応答(VQA)、Microsoft COCO画像キャプション、最新オブジェクトキャプション(nocaps)などがある。さらに、Microsoft VLシステムは、CIDErの点でnocapsリーダーボードでの人間のパフォーマンスを大幅に上回っている(92.5対85.3)。
MicrosoftはVLタスク用のオブジェクト属性検出モデルをトレーニングした。トレーニングは、1,848個のオブジェクトクラスと524個の属性クラスの249万個の画像を含む大きなオブジェクト検出データセットを使用し、4つのパブリックオブジェクト検出データセット(COCO、Open Images、Objects365、VG)をマージすることにより行った。彼らは最初に、結合されたデータセットでオブジェクト検出モデルを事前トレーニングした。次にVGの追加の属性ブランチを使用してモデルを微調整し、オブジェクトと属性の両方を検出できるようにした。その結果、モデルは1,594個のオブジェクトクラスと524個の視覚的属性を検出できるようになった。さらに、ブログ投稿によると、研究者による実験では、モデルは入力画像内の意味的に有意な領域をほぼすべて検出してエンコードすることができる。
ブログ投稿で、著者は次のように述べている。
画像キャプションベンチマークで人間のパフォーマンスを超えるなど有望な結果を得えましたが、私たちのモデルは、VL理解について人間レベルのインテリジェンスに決して到達していません。今後の作業について興味深い方向性として、(1)大量の画像分類/タグ付けデータを活用することにより、オブジェクト属性検出の事前トレーニングをさらにスケールアップすること、(2)クロスモーダルVL表現学習の方法を拡張して、知覚に基づいた言語モデルを構築することが挙げられます。知覚に基づいた言語モデルでは人間のように、自然言語で視覚的概念を理解することができ、その逆も可能です。
最後に、Researchブログで、同社はVinVLモデルとソースコードを一般に公開すると発表した。詳細については、リサーチペーパーとGitHubリポジトリのソースコードをご覧ください。さらに、MicrosoftはVinVLをAzure Cognitive Services製品に統合する予定である。