AWSは、Amazon OpenSearch Serverless内のベクトルストレージと検索機能のプレビューリリースを発表した。この機能は、機械学習によって拡張された検索体験と生成AIアプリケーションをサポートすることを目的としている。
Amazon OpenSearch Serverlessは、Amazon OpenSearch Serviceで提供されているサーバーレス製品だ。オープンソースの検索プロジェクトApache LuceneをベースにしたAmazon OpenSearchは、JSONドキュメントの取り込み、保存、検索、分析を可能にする。
歴史的に、Luceneベースのシステムにおける検索は、結果の関連性を制御するためのスコアリング指標とともに、キーワードマッチングに依存してきた。キーワードマッチングは、用語の転置インデックスを構築し、その用語が出現するドキュメントにリンクすることで機能する。一方、結果のランク付けは、個々の文書を疎なN次元空間内のベクトルに変換することで行われる。各次元の重みはスコアリング指標からの出力であり、次元は考慮されるすべての文書にわたる用語である。このアプローチは、しばしば語彙検索と呼ばれるが、効率的である反面、クエリに意味的に答えているので重要な用語が省略され文書を除外される。ベクトル検索は、この制限を克服することを目的とした新しいアプローチである。
ベクトル検索では、クエリは変換モデルによって密なベクトルに変換され、類似したベクトル表現を持つ文書を特定し検索結果を得られる。
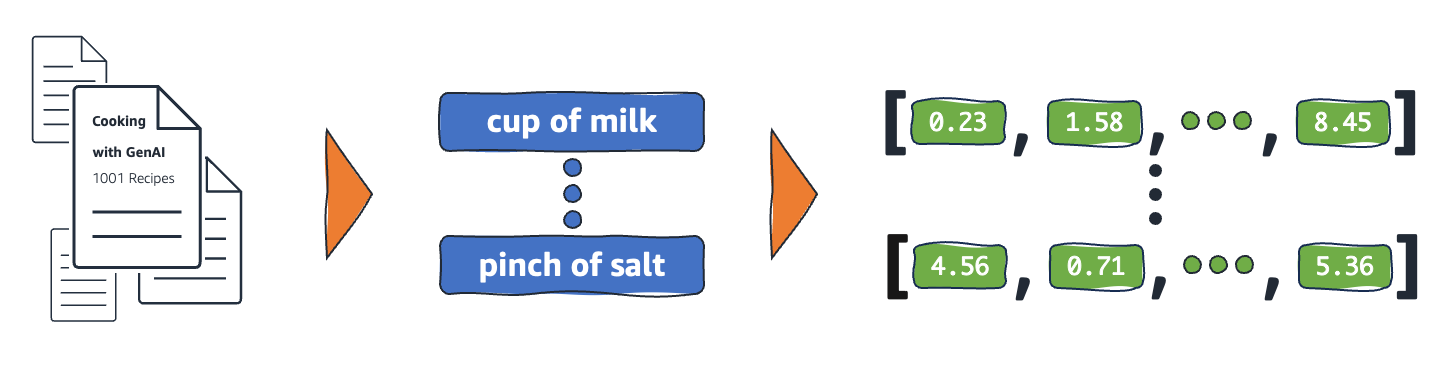
テキストがどのようにベクトル埋め込みとして表現されるかの図(出典:AWS NewsBlog Post)
このため、埋め込みと呼ばれるこれらのベクトルに適切なインデックスを付け、隣接するベクトルの検索によって類似性を特定できるストレージシステムが必要となる。この機能を提供するのが、Amazon OpenSearch Serverless用のベクトルエンジンだ。
新しいエンジンでは、最大16,000次元の埋め込み用のベクトルインデックスが、ユークリッド、コサイン、ドット積の類似度指標とともに作成できるようになった。ベクトル場に加え、新しいインデックスでは、検索フィルター用のコンテキストメタデータとして、各文書に最大1000のフィールドを持たすことを可能とした。
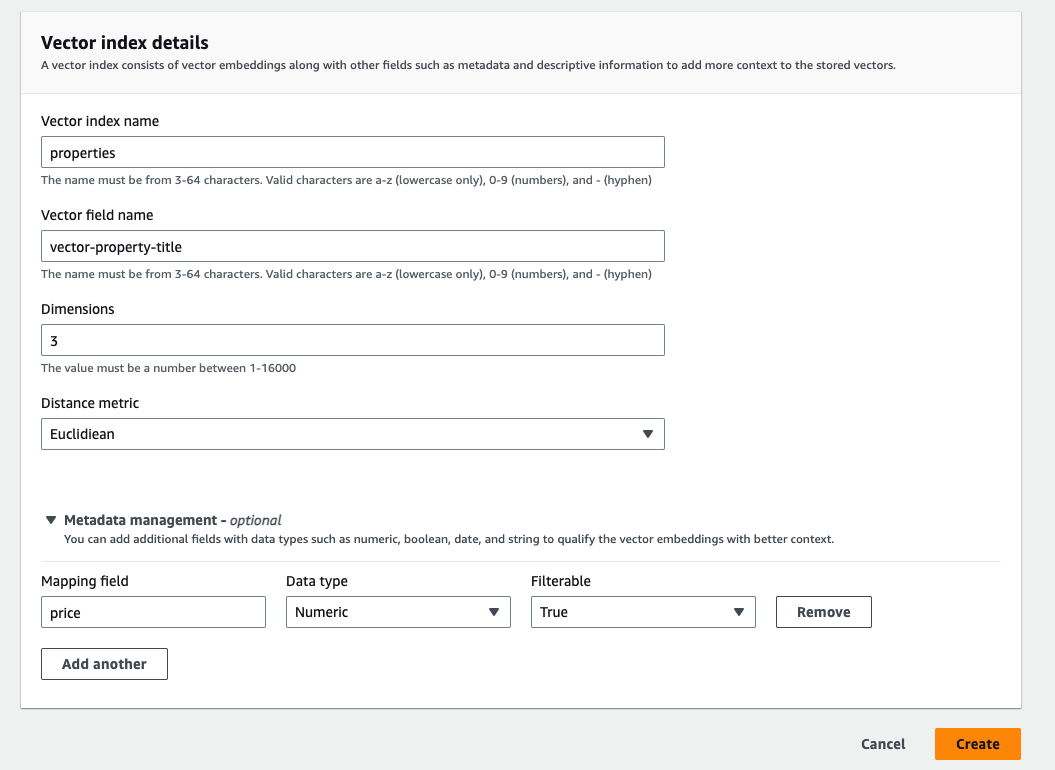
AWS Console上のベクトルインデックス作成ページのスクリーンショット(出典:AWS NewsBlog Post)
OpenSearch Serverlessアーキテクチャを活用することで、ベクトルエンジンは、ユーザが基盤となるインフラ上でサイジング、チューニング、スケーリングコントロール実装の必要性をなくす。また、OpenSearchスイートAPIもサポートしており、既存の語彙検索、フィルタリング、集約、地理空間クエリ機能をベクトル検索と同時に使用できる。
/filters:no_upscale()/news/2023/08/vector-engine-opensearch-preview/en/resources/1Captura%20de%20pantalla%202023-08-20%20a%20las%2017.00.52-1692547443767.png)
ベクトル検索と語彙検索を組み合わせたOpenSearchクエリのスクリーンショット(出典:AWS NewsBlog Post)
OpenSearch Serverlessとの緊密な統合の欠点は、ベクトルエンジンの使用には、他のワークロードと同様に4つのOpenSearch Compute Units(OCUs)という同じ最低条件が課せられることだ。Amazon Opensearch Serverlessに関するコミュニティからのフィードバックは、主にその比較的高いコストに集中しており、r/awsのスレッド上でユーザーであるralusek氏が コメントしている。
"......最低700ドル/月とは......いじくり回すには、ばかばかしいほど高い......。"
Amazon Opensearch Serverlessチームは、1OCUを最低条件とする将来的な計画を発表しているとおり、ユーザーの問題点を理解しているようだ。チームはまた、サービスの一般提供に先立ち、顧客の実験を可能にするため、毎月1400OCU時間を無料で提供している。
同様の生成AIや機械学習ワークロードの場合、Amazon Opensearch Serverless用のベクトルエンジンの代替は、pgvector拡張を持つPostgreSQL、Elasticsearch Vector Search、Pineconeだろう。
最後に、Amazon OpenSearch Serverless用のベクトルエンジンを使い始める方法についての詳細情報は、ドキュメントページで確認できる。